
当記事では畳み込みニューラルネットワーク(Convolutional Neural Network;CNN)の基本的な理論とPyTochを使った実装について解説していきます。
おおまかな構成は、畳み込みニューラルネットワークの起源、畳み込みニューラルネットワークの理論(具体的には、畳み込み、プーリング、全結合層について)、PyTorchを使用した実装、参考文献となります。学習方法の理論に興味のある方に向けた記事は後々投稿する予定です。
当記事は結構長いですので、興味のあるところから読んでみてください。
また、この記事の内容を前半(畳み込みニューラルネットワークの起源と理論)と後半(PyTorchによる実装)に分けて動画で解説しています。もしよければ動画の方もご視聴してみてください。
当サイトはTwitterやYouTubeでも情報発信しています。ご気軽にフォロー(@AGIRobots)、チャンネル登録お願いします!
畳み込みニューラルネットワークとは
畳み込みニューラルネットワーク(Convolutional Neural Network;CNN)とは主に画像認識の場で利用されるディープニューラルネットワークで、深層学習分野において大きな柱を成しています。
簡単な例として畳み込みニューラルネットワークを使用した画像識別タスク(クラス分類)について考えます。以下のアニメーションにおいて識別モデル(discriminative model)の部分に畳み込みニューラルネットワークを適用し、出力層をクラス分類器にすることで識別結果を学習&出力することができます。実は、識別モデルの部分を畳み込みニューラルネットワークにする必要はなく、一般的な全結合ニューラルネットワークでも構いません。しかし、画像認識タスクでは、空間的な特徴を扱うため、パラメータ数が膨大になること、また移動不変性などの画像識別の特徴により畳み込みニューラルネットワークが優位となっています。
※図ではdiscriminative modelと書きましたが、クラス分類器(classifier)と考えていただいて大丈夫です。discriminative modelはgenerative modelの対義語で、敵対的生成ニューラルネットワーク(Generative Adversarial Networks;GAN)で頻繁に登場します。

最近では、畳み込みニューラルネットワークを画像認識タスク以外、具体的には自然言語処理といった領域で使用されるなど注目をされています。それでは、畳み込みニューラルネットワークについて、その起源、理論、実装について順番に説明していきます。
畳み込みニューラルネットワークの起源
畳み込みニューラルネットワークは生物の脳の視覚野をモデル化したネオコグニトロンが基となり、それを機械学習モデルの学習スタイルに適合する形でモデル化したLeNetが起源となります。ネオコグニトロンは視覚野の単純型細胞と複雑型細胞の処理に注目しモデル化されているので、この章では単純型細胞と複雑型細胞にも触れつつ、ネオコグニトロン、LeNetについて説明します。内容は、かなり前に備忘録として適当にまとめた記事の一部分を抜き出したもの+αとなっています。以下にリンクを貼ります。
単純型細胞(S細胞)と複雑型細胞(C細胞)
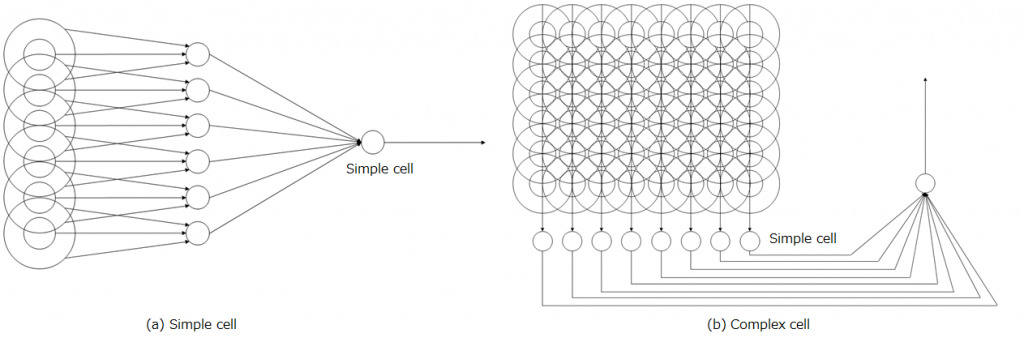
単純型細胞(以下:S細胞)とは特定の傾きの線分にのみ反応を示す特徴を持っています。複雑型細胞(以下:C細胞)とは、C細胞がもつ受容野内におけるS細胞の出力の位置ずれを許容する特徴があります。
S細胞に情報を入力する外側膝状体の神経細胞は、同心円状の受容野を持っており、例えば注目しているS細胞が縦線を認識するなら、縦方向に並ぶような位置関係にあるニューロンを入力として持つことで、縦線を認識できるようになります。
次に縦の線分の位置ずれを許容するC細胞を考えます。このC細胞は受容野内のS細胞のなかでも、縦の線分を認識する複数のS細胞を入力としてもち、その中のどれか1つでも反応を示せば、縦の線分の位置ずれを許容するC細胞が発火します。
以下の図は今の説明を図示したもので、(a)は単純型細胞のモデル、(b)は複雑型細胞のモデルです。
少し話が逸れますが、視覚野において低次な情報処理を行う部位には、傾きが少しずつ異なる線分に反応を示す細胞群がコラムを形成しており、そこでは入力された画像データを傾きの線分情報に分割していると考えられます。これはS細胞と考えることができます。そして、それをC細胞で位置ずれの許容をしながら、S細胞層とC細胞層を何度も繰り返して入力画像の再構築をしていくと考えられています。高次の情報処理では四角形や渦巻といった特定の形状に反応する細胞が現れたり、特定の人の顔に反応する細胞が現れたりします。これは、おばあさんニューロン仮説と関連があると思われます(恐らく...しっかり学んでいないのでこの程度でお許しを...)。
ネオコグニトロン
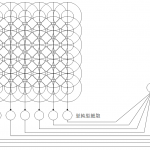
先ほど、視覚野ではS細胞層とC細胞層を何度も繰り返すことで画像情報から特徴を抽出し、上位層で識別していることを説明しました。これをモデル化したものが福島邦彦さんにより提案されたネオコグニトロンです。まず、前半の2層ではコントラストの抽出を行い、入力画像からエッジを識別しやすいように変換します。この処理は網膜部分に対応します。その後に、S細胞層とC細胞層が4サイクル繰り返されます。学習には一般的なニューラルネットワークで使用される誤差逆伝播とは異なる、Add-if-silentという方法が使用されます。
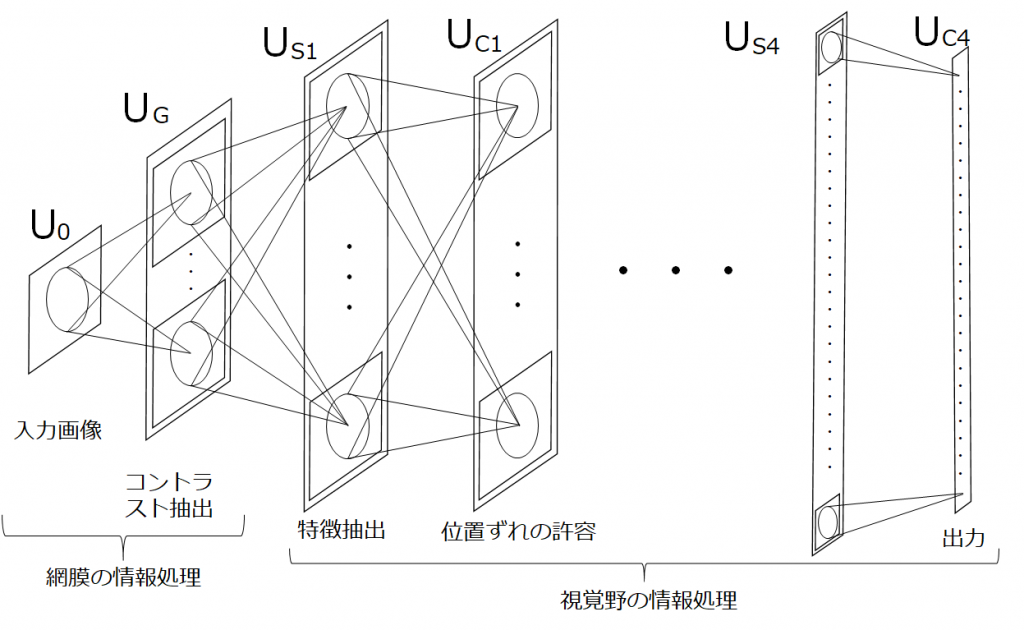
LeNet
ネオコグニトロンでは特徴抽出をする層と位置ずれの許容をする層をS細胞層とC細胞層と表現しました。LeCunらによって提案されたLeNetでは畳み込み層、プーリング層(LeNetの場合、正確にはサブサンプリング)という表現に変わります。また学習方法は、Add-if-silentではなく誤差逆伝播を使用します。LeNetは現在の畳み込みニューラルネットワークのほぼ完全な基本形です。
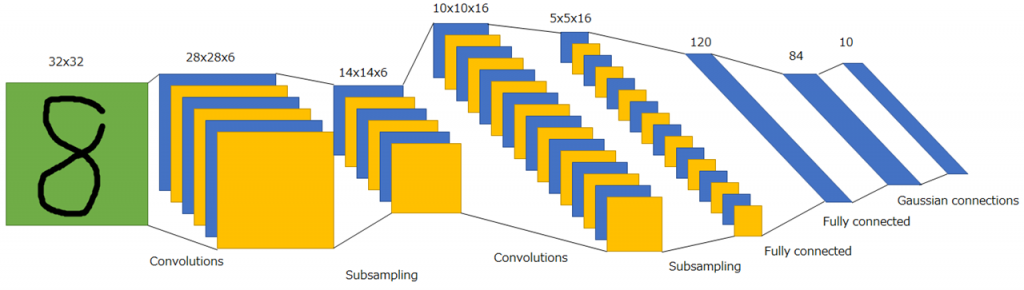
図では畳み込み層またはプーリング層を通過する前後の特徴マップが示されていることに注意してください。画像処理において特徴マップとは縦・横・深さの3次元で表されます。畳み込み層とプーリング層の説明をしていないので、今は理解できなくても大丈夫ですが、LeNetでは入力画像(32x32x1の特徴マップ)に6種類の畳み込みフィルタを適用し28x28x6の特徴マップを得ます。それにプーリング処理を施し14x14x6の特徴マップを得ます。このような処理を再度繰り返し、最後に全結合層に接続されます。全結合層は畳み込みニューラルネットワークの構造自体と直接的な関係ありませんが、識別及び回帰において重要な役割を果たすため、ほぼ確実に使用します。
畳み込みニューラルネットワークと全結合ニューラルネットワークの関連性
これまでの説明で、畳み込みニューラルネットワークの誕生過程を理解していただけたと思います。ここでは、畳み込みニューラルネットワークと全結合ニューラルネットワークがどのように似ていて、また異なるのか説明します。畳み込みニューラルネットワークを1列に展開した以下の図を見てください。
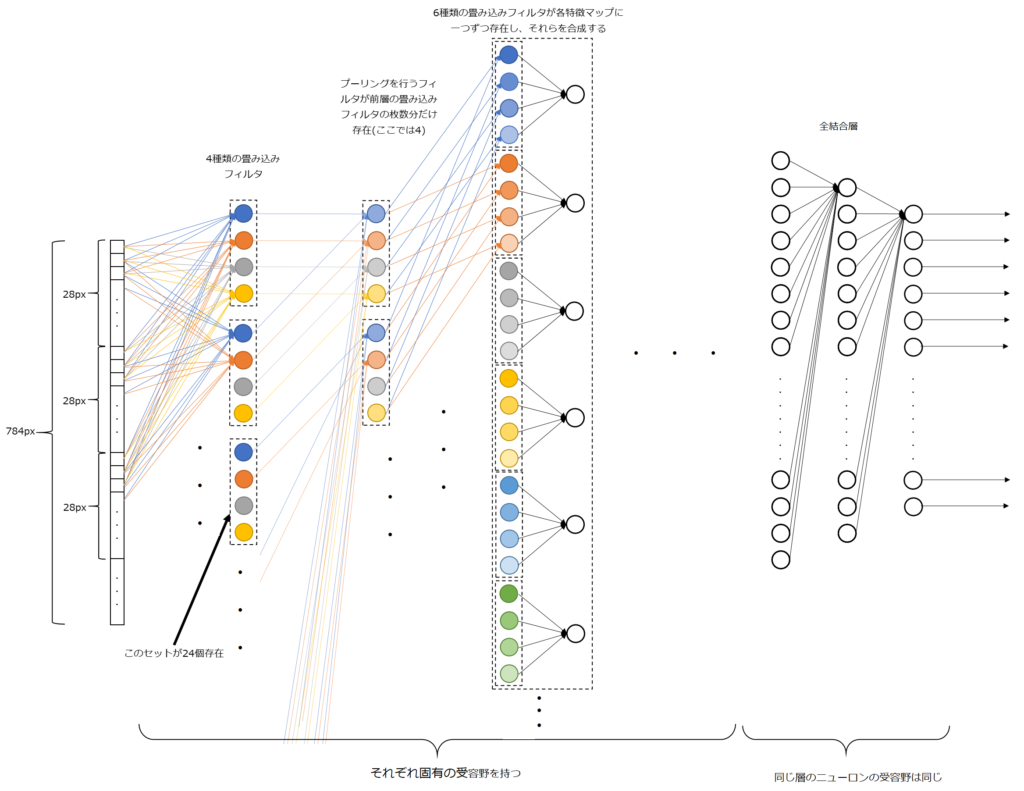
畳み込みニューラルネットワークと全結合ニューラルネットワークの構造的な違いは前層のニューロンと結合している領域が局所的であるかどうかです。これは、局所的受容野といわれ、畳み込み層の大きな特徴の1つです。局所的受容野は結合できるニューロンの領域に制約を課しています。
プーリング層も同様で、受容野は局所的です。一方で、全結合層は前層の全ニューロンと結合しているため、パラメータが爆発的に多くなり、また空間的な特徴を学習するのに不利であることが予測できます。
図では畳み込み層のニューロンを全て描き表せていないのイメージが湧きにくいと思いますがですが、実は、畳み込み層では各特徴マップを受容野の大きさ(フィルタサイズ)に応じてパッチに分割し、各々のフィルタを全パッチに対して一括で処理を実行するため、パッチの位置によってフィルタの重みが異なることはなく、これを重み共有といいます。つまり、1つのパッチで得られた畳み込みフィルタのニューロンは全体のバッチに複製されていることと等価になるため、全結合層で実現するよりも効率的に空間的な特徴の学習が行え、さらにパラメータの大幅な減少に貢献しています。
まとめると、畳み込みニューラルネットワークは局所的受容野と重み共有により、大幅にパラメータを減少させていることに成功したといえます。パラメータ数が減少すれば計算コストが少なくて済みますし、精度を出すために必要な学習データ数も少なくて済むため一石二鳥ですね。
ちなみに、全結合ニューラルネットワークは密結合ニューラルネットワークと呼ばれることがあることを考慮すると、畳み込みフィルタやプーリングフィルタは疎結合ニューラルネットワークといえます。
畳み込みニューラルネットワークの理論
この章ではある程度数式を交えた説明をしていきます。主に説明する内容は畳み込みニューラルネットワークの中心的な演算である畳み込みとプーリングです。この章の最後で簡単に全結合層についても説明します。
この章では、先ほど少し触れましたが特徴マップの深さ(チャンネル数)を意識して読んでいただけるとコーディングの際に理解が楽になります。
畳み込みフィルタによる特徴抽出
畳み込みフィルタの働きを最も抽象的に表現すると、「周辺の画素を考慮して(重み付けして)ぼかす」操作ということになります。
畳み込み層の特徴
畳み込み層の重要な特徴は先ほど畳み込みニューラルネットワークの特徴として説明したものと同じですが、以下の2つになります。
- 局所的受容野
- 重み共有
再度、簡単に説明すると、1つ目の局所的受容野は、フィルタの適用範囲(受容野)を制限していることを表しています。対して、全結合ニューラルネットワークの受容野は前層の全ニューロンとなることが自明なため受容野という概念はとりわけ問題にされません。2つ目の重み共有とはフィルタの重みが特徴マップのパッチ全体に適用されることを示しています。これらの2つの特徴は、チューニング対象となるパラメータ数を大幅に減少させることに寄与したという共通点があります。
畳み込みフィルタで線分検出を試す
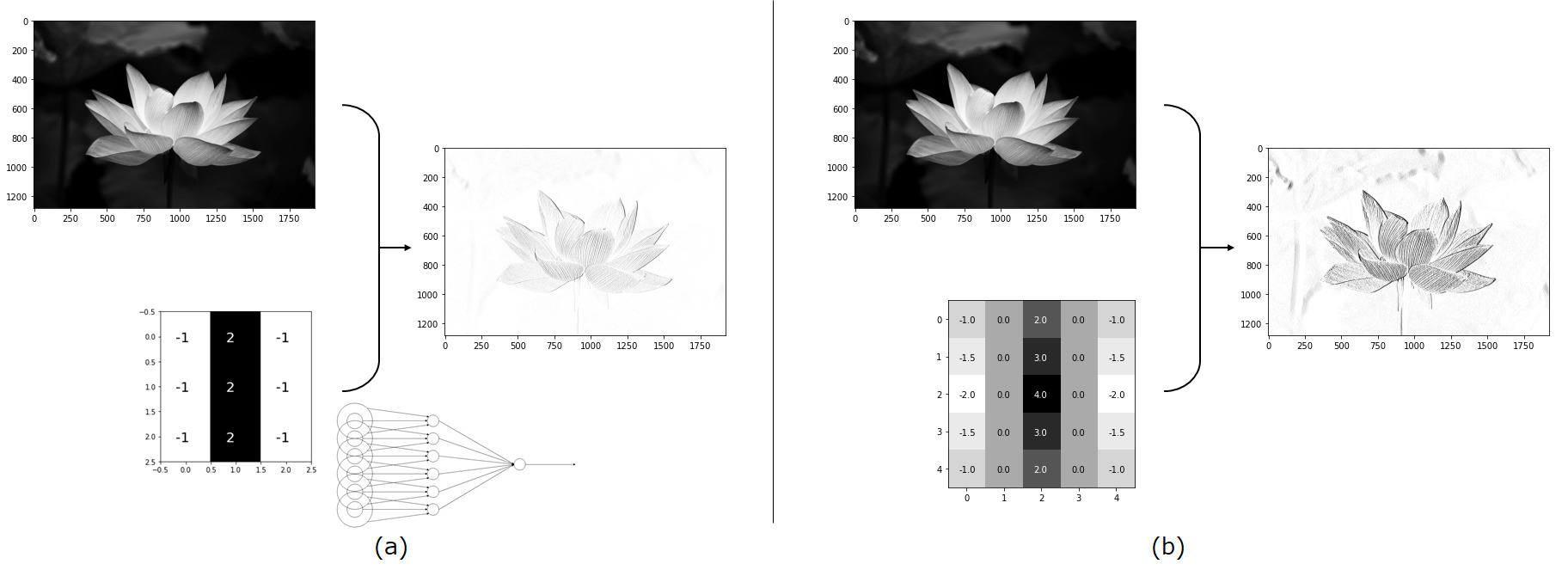
前章でフィルタはS細胞の働きをすると説明しました。では、本当にS細胞と同じ働きが実現できるのか確かめてみます。以下の(a)図を見てください。下に示したフィルターがS細胞を表したものになります。比較しやすいように(a)の右下に小さくS細胞のモデルを示しました。中心部分と周辺部分が拮抗するような値を持つフィルタを写真に適用すると写真内の縦の線分検出ができていることが分かります。(b)図はフィルタを大きくし、中心部と周辺部の重みを緩やかにしたものになります。これはS細胞の受容野を広くしたことに対応します。フィルタの大きさ、すなわち受容野の大きさによって検出の強調度合いが異なることが分かります(※必ず大きい方が性能が高いと言っているわけではありません)。
畳み込みフィルタの計算方法
畳み込み層の計算方法を述べる前にパディング、ストライド、パッチについて説明します。
- パディング
画像の端にフィルタを適用できるように数値を埋める処理 - パッチ
畳み込みフィルタおよびプーリングフィルタの処理で適用される領域・範囲 - ストライド
フィルタを何マスずつスライドさせるのか間隔を設定
パディングについて
特徴マップ(ex:画像)が入力されたとき、畳み込みフィルタをマップ上の端に位置するピクセルに適用したいとします。しかし、端のピクセルは周囲が値を持つピクセルとは限らないため、どのように畳み込みフィルタを適用したらよいのか困ります。そこで以下の図のように周囲に値をもつピクセルを追加することで、入力された特徴マップの端にもフィルタを適用できるようにします。これをパディング(padding)といいます。
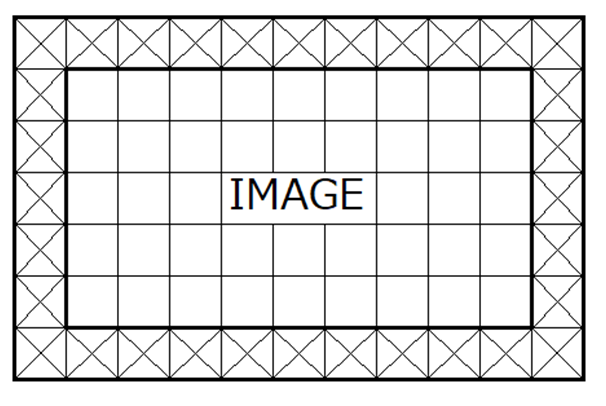
この図は、特徴マップとして画像が入力された時に、周囲の×で示した領域を追加した例を示しています。xの部分には値が埋められ、その値は0のような固定値だったり、あるいは、ある処理を施して求まる値だったりします。0で埋められる場合は、ゼロパディングといわれます。
また、周囲1ピクセル分のみのパディングとは限らず、2ピクセル分のパディングを行ったりします。それは出力として同じ高さと幅の特徴マップを得たい場合、使用するカーネルサイズによって必要なパディングのサイズが異なるためです。kerasでは引数paddingにsameを指定することで、入力特徴マップと出力特徴マップの高さと幅を等しくすることができます。PyTorchでは周囲何ピクセル分パディングを行うか自身で計算し、引数paddingに指定する必要があり、デフォルトではパディングが行われない(padding=0)ようになっています。
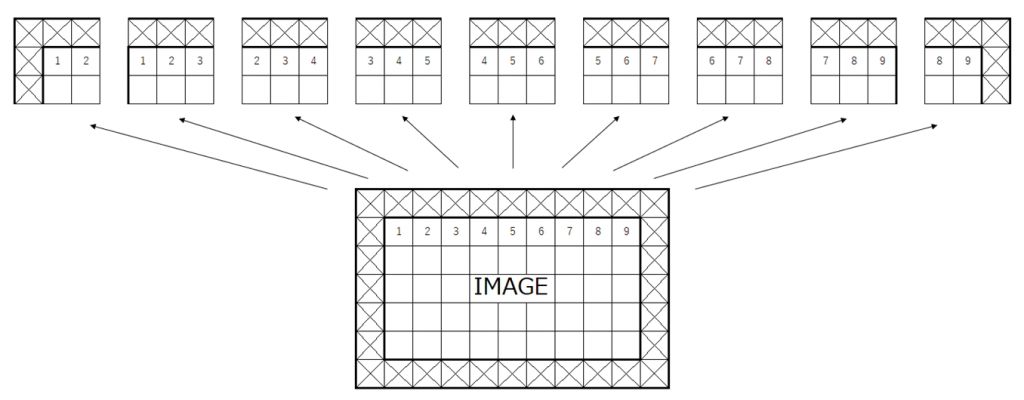
パッチについて
パッチとは、フィルタが適用される各領域ごとに分割したものです。以下の図の場合は、3x3のフィルタをストライド=1で最上位のピクセルの行に適用した場合のパッチを示しています。畳み込みフィルタのカーネルサイズによりパッチの大きさは変化し、ストライドの程度によってパッチの位置も変化します。
ストライドについて
上で少しストライドについて触れましたが、ストライドとはフィルタを適用する間隔を決定するパラメータです。例えばストライドが2の場合はパッチは以下のようになります。ストライドが1のときは、パッチの中心に位置するピクセルが、1,2,3,…という順番になっていましたが、ストライドが2の場合は、1,3,5,…と2つ飛びになります。そして、パッチの数は減少します。
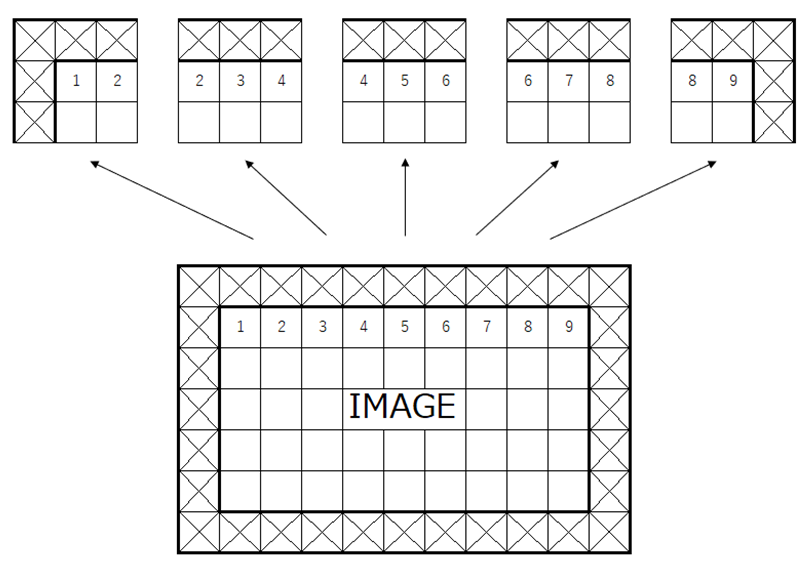
※図ではパディングの内側をIMAGEとしていますが、ここは特徴マップと一般化として説明する方が相応しいですね(図を作成した後に気づきました)。
ここまでの内容を踏まえたうえで、畳み込みフィルタの処理を表す式を見てみましょう。カーネルサイズが\( (2N+1)×(2N+1)\)のフィルタ\(F\)と、深さ=1の入力特徴マップ\(I\)を用意します。また、フィルタ\(F\)の各成分を\(F_{ij}\)、\(I\)の各成分を\(I_{ij}\)とします。このとき、フィルタを適用した結果\(I'\)の\((x, y)\)成分\(I'_{xy}\)の値は以下の式で一般化されます。
$$
I'_{xy} = \sum_{i=-N}^N\sum_{j=-N}^NI_{sx+i, sy+j}F_{i+N, j+N}
$$
\(s\)はストライドを表しています。以下の図に示す、ゼロパディングで3x3のフィルタによる畳み込みの場合を例として計算をしてみます。ただし、ストライド\(s=1\)とします。
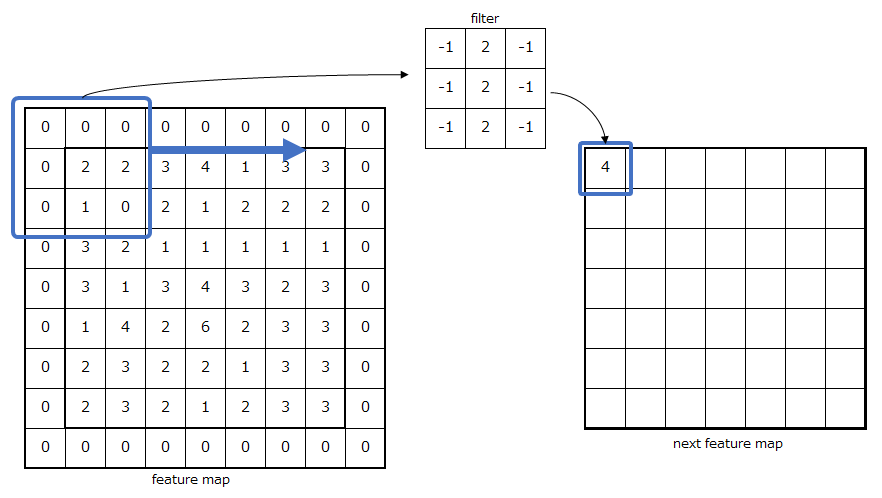
この場合、先ほどの式は
$$
I'_{00} = \sum_{i=-1}^1\sum_{j=-1}^1I_{i, j}F_{i+1, j+1}
$$
で表され、展開すると、
$$
\begin{eqnarray}
&&0×(-1)+0×2+0×(-1)+0×(-1)+2×2+2×(-1)+0×(-1)+1×2+0×(-1)\\
&=&4-2+2\\
&=&4
\end{eqnarray}
$$
となります。パッチとフィルタの対応する成分同士が掛け合わされたのちに加算するだけです。
※ここでは活性化関数が省略されていますが、間違っているわけではありません。ライブラリによって畳み込み処理内に含めているものや含めていないものがあります。kerasでは畳み込みレイヤの引数activationにreluなどの活性化関数を適用することで直接適用結果が得られますが、PyTorchでは、畳み込み処理の関数内に活性化関数が含まれていないため、torch.nn.finctional.relu()などを使用して結果に適用する必要があります。この記事ではPyTorch型を使用しました。
畳み込み層と特徴マップの変換
先ほどは、最も単純な畳み込みフィルタによる特徴マップへの写像を示しました。それは、深さ=1の特徴マップに対し、一種類のフィルタを適用いて深さ=1の特徴マップを出力するものでした。しかし、実際はもっと複雑です。そのため、ここでは入力特徴マップと出力特徴マップの変換を畳み込みフィルタのチャンネル数や枚数と関連付けて一般化したいと思います。
白黒画像(特徴マップの深さ=1)を入力した場合
以下の図を見てください。ここでは、入力特徴マップとして白黒画像、すなわち深さが1の特徴マップに4種類の畳み込みフィルタを適用する場合を考えています。フィルタが適用された後に出力されたそれぞれのマップは深さ方向に4枚重ねられます。ちなみに特徴マップの深さ軸はチャンネル数ともいわれます。
それぞれの畳み込みフィルタは縦の線分の認識や横の線分の認識といった特定の特徴認識に特化していおり、それらを適用することで個々の特量が抽出されたマップが出力され、それを深さ方向に重ねたものとなっています。
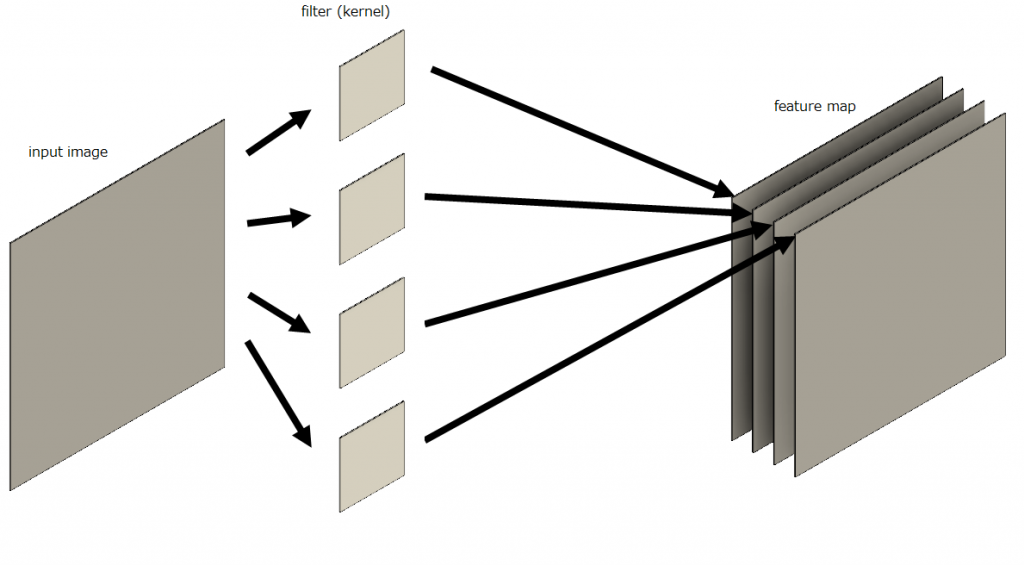
RGB画像(特徴マップの深さ=3)を入力した場合
次にRGB画像を入力特徴マップとした場合を考えます。つまり入力特徴マップのチャンネル数は3です。先ほどと同様に4種類の畳み込みフィルタを適用することを考えるのですが入力特徴マップの深さが3なので、各種類のフィルタのチャンネル方向に入力特徴マップのチャンネル数分のフィルタを持たせます。以下では分かりやすいように色分けがしてあります。同じ色のマップとフィルタ同士が畳み込み処理されます。そのため、各フィルタを通過したばかりの特徴マップは入力特徴マップと同じチャンネル数を持ちます。そのあと、深さ方向で各要素同士が足し合わされて(以下の画像⊕部分)、チャンネル数1になったものが、最後に重ねられて深さが4の特徴マップが完成します。
(うまく説明できないので、動画の方をご覧ください...)
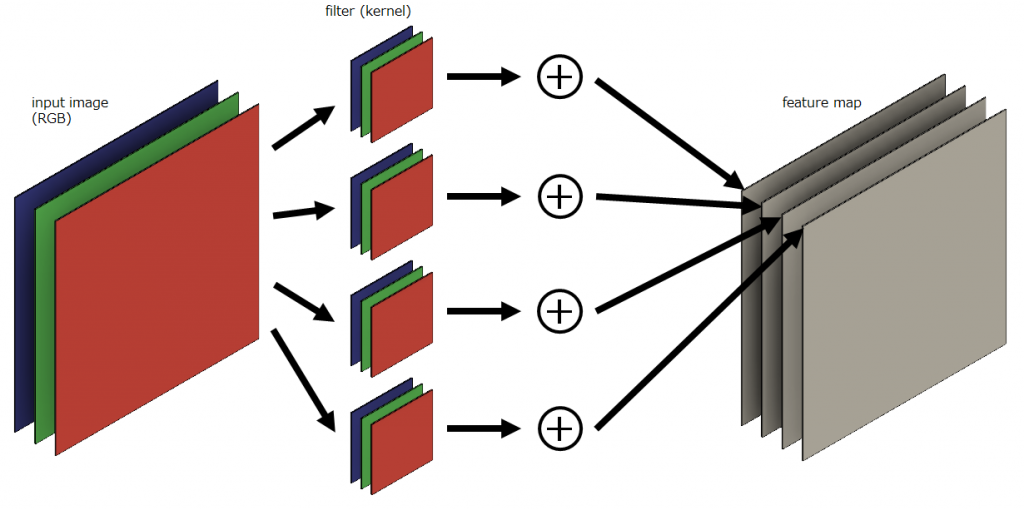
特徴マップの変換を一般化
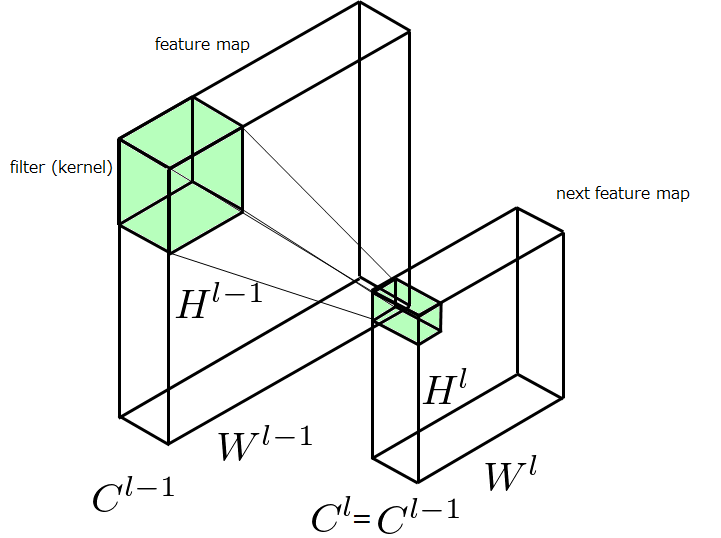
以上の変換を一般化していきます。以下のように、\(l-1\)番目の特徴マップ\((H^{l-1}, W^{l-1}, C^{l-1})\)を入力として受け取り、畳み込みフィルタで変換を施し、\(l\)番目の特徴マップ\((H^l, W^l, C^l)\)を出力する場合を考えます。このとき、各フィルタの深さは\(C^{l-1}\)に、フィルタの枚数は\(C^l\)になります。すなわち、フィルタの枚数を指定すれば自ずと出力される特徴マップのチャンネル数は決定します。また、\(W^{l-1}=W^l, H^{l-1}=H^l\)になるように調節することが多いです(kerasではpadding='same')。
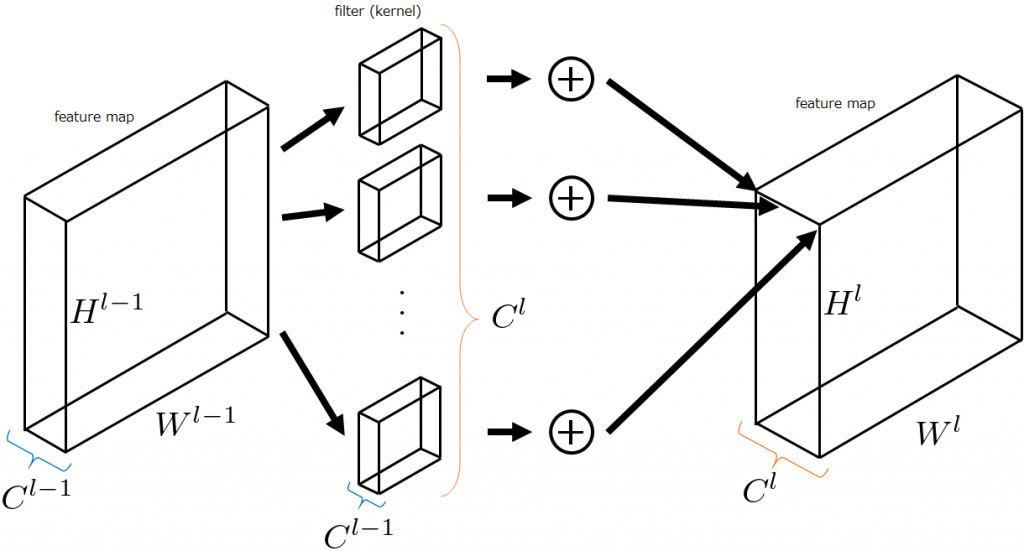
これを数式で表してみましょう。
$$
I_{xym}^l=\sum_{k=1}^{C^{l-1}}\sum_{i=-N^{l-1}}^{N^{l-1}}\sum_{j=-N^{l-1}}^{N^{l-1}}I^{l-1}_{sx+i, sy+j, k}F_{i+N^{l-1}, j+N^{l-1},k,m}
$$
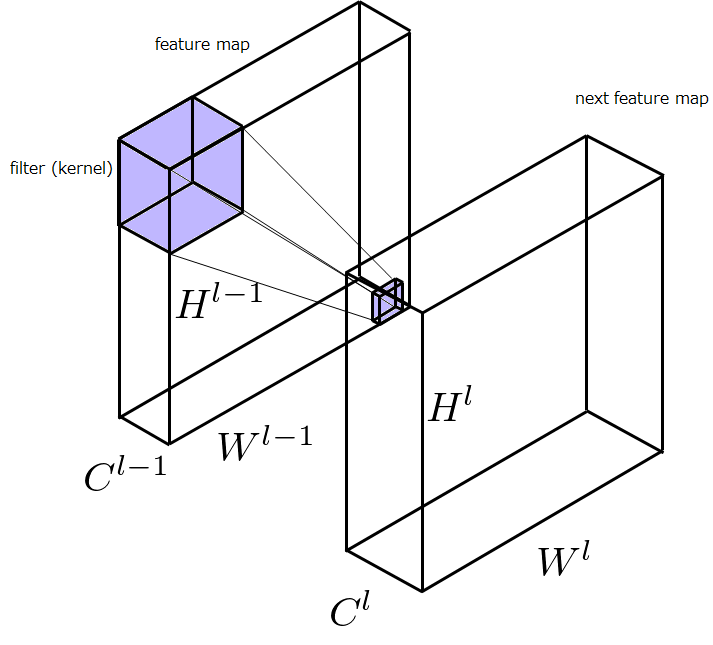
結構複雑に見えますが簡単です。入力特徴マップを\(I^{l-1}\)、\(I^{l-1}\)に適用する畳み込みフィルタの各カーネルサイズを\((2N^{l-1}+1)×(2N^{l-1}+1)\)、出力される特徴マップを\(I^l\)と書き換えたのち、畳み込みフィルタの種類のインデックスを表す\(m(1\leq m\leq C^l)\)、チャンネル軸のインデックスを表す\(k(1\leq k\leq C^{l-1})\)を追加して、足し合わせる操作を行っているだけです。この式が行っている処理を図示すると以下ようになります。図においてfeature mapの一部に色が塗ってありますが、それがパッチです。このパッチ1つ分が先ほど示した式の処理が行われる領域で、そこからnext feature map上の一点の値が求められます。深さ方向に足し合わせる処理は、特徴マップの深さ方向に分割されている特徴をマージし、層間の関連性をもたせることに貢献します。
プーリング処理による位置ずれ許容
プーリング層の特徴
プーリングフィルタの処理の最も重要な特徴は
- 位置ずれの許容(位置情報を荒くする)
です。位置ずれを許容する処理は特徴マップの高さと幅を小さくする際に、最大値以外の値は間引くなどの処理を行うことで実現できます。
特徴マップの高さと幅を小さくしたいだけの場合、Depthwise畳み込み層というものを使用してストライドを1以外の正数にすればプーリングに近い処理が実現できる可能性はありますが、畳み込み層は学習によりパラメータが変化するため、最大値を抜き出したい、などの特定の処理を実現したいときにプーリング層という手法を使用する必要があります。
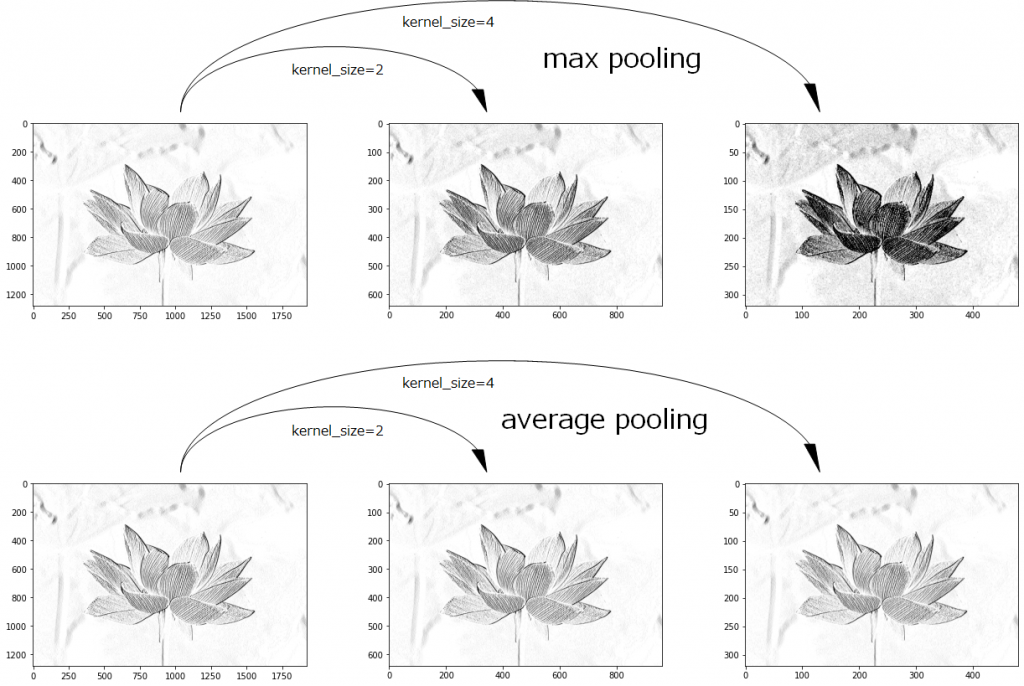
プーリングフィルタを試す(maxプーリングとaverageプーリング)
先ほど縦の線分を認識する畳み込みフィルタで線分を抜き出した特徴マップ(特徴が強調された画像)にプーリング処理を適用したいと思います。以下の図を見てください。上の図が最大値プーリング、下の図が平均値プーリングを適用したものです。また、左の列の図にカーネルサイズ2x2を適用したものが中央の列で、左の図にカーネルサイズ4x4を適用したものが右の列の図になります。最大値プーリングでは、縦の線分を認識する畳み込みフィルタが強く反応を示したところをパッチ内で抽出し、グッと圧縮しているため、その特徴が色濃く表れていることが分かります。一方で、平均値プーリングはパッチ内で色を薄めた感じになっているだけで、いまいちパッとしませんね。特徴マップの縦横を小さくしただけのように感じます。特徴の位置が移動してもそれを打ち消す緩衝材のような働きをするC細胞はどちらかといえば最大値プーリングに近いと思われます。
※最大値プーリングが必ずしも優れているとはいえなくて、最近では最大値プーリングと平均値プーリングを重み付けして使用するものがあるようです。
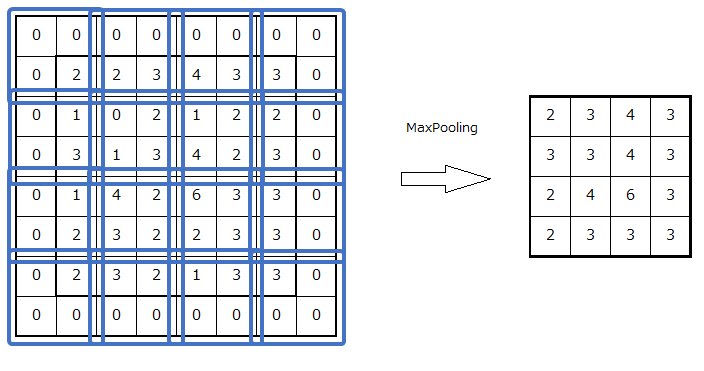
プーリングフィルタの計算方法
それではプーリング層の計算方法として、代表的な最大値プーリングと平均値プーリングを扱おうと思います。
最大値プーリング
まず、畳み込み層から出力された特徴マップ\(I^{l-1}\)を活性化関数\(f\)で変換します。そして、プーリングフィルタが適用される位置\((i, j)\)が指すパッチの内部に位置する座標\((p, q)\)を集合\(P_{ij}\)として、以下のように表されます。
$$
I_{ijm}^l = \max_{p,q\in P_{ij}} f(I_{pqm}^{l-1})
$$
平均値プーリング
適用されるプーリングフィルタの一辺の大きさを\(K\)として、
$$
I_{ijm}^l = \frac{1}{K^2}\sum_{p,q\in P_{ij}} f(I_{pqm}^{l-1})
$$
と表されます。パッチ内の値が足し合わされて、フィルタサイズで正規化することで、平均値を求めます。
プーリング層と特徴マップの変換
プーリングでは畳み込みフィルタのように特徴マップのチャンネル軸で足し合わされる操作はないため、入力される特徴マップのチャンネル数と出力される特徴マップのチャンネル数は同じになります(\(C^{l-1}=C^l\))。また、カーネルサイズが2x2であれば、ストライドのデフォルト値は2になります。\(W^l\)や\(H^l\)はストライド\(s\)により大まかな大きさが決定し、それぞれ約\(\frac{W^{l-1}}{s}\)と\(\frac{H^{l-1}}{s}\)になります。
全結合層の計算
全結合層は、入門書などで真っ先に扱う最も単純な順伝播型ニューラルネットワークです。すべてが密に結合しているので、式も単純です。
\(l-1\)層目からの入力および\(l\)層目の出力を\(\boldsymbol{x}^{l-1}, \boldsymbol{x}^l\)、重み行列を\(\boldsymbol{W}^{l-1}\)、バイアス行列を\(\boldsymbol{b}^{l-1}\)、活性化関数を\(f\)として、
$$
\boldsymbol{x}^l = f(\boldsymbol{W}^{l-1}\boldsymbol{x}^{l-1} + \boldsymbol{b}^{l-1})
$$
と表されます。ここで、次元を大きくして\(\boldsymbol{x}\)の成分\(x^{l-1}_0=1\)とするテクニックを使用するとバイアス項が消去でき、完全な線形写像で表現可能になります。

PyTorchによる畳み込みニューラルネットワークの実装
この章ではPyTorchを使用してCIFAR10のクラス分類を行うモデルを前半で説明したLeNetを参考に実装していきたいと思います。この章の構成は、CIFAR10について、プログラムの概要、プログラム、実行結果の表示です。
CIFAR10について
CIFAR10とは、10クラス分類問題のために作成された、32x32ピクセルのカラー画像によるデータセットで、1クラスにつき6000枚の画像が含まれています。全クラスでは60000枚になります。含まれている画像は、airplane,automobile,bird,cat,deer,dog,frog,horse,ship,truckで、以下の画像に示すようなものになります。32x32ピクセルだと、ぼやけていて少しわかりにくいですね。
ちなみに、CIFAR100というものもあり、こちらは100クラス分類問題に使用されます。ただ、各クラスに対応する画像の枚数は、600枚と少なくなります。

プログラムの概要
今回作成するプログラム作成にあたり、大まかな概要を示します。
- 必要なライブラリ・モジュール等のインポート
- モデルの定義および学習に必要なもの
- データの読み込みに必要なもの
- 結果の可視化に必要なもの
- モデルのクラスを定義
- モデルのインスタンス化
- モデルのサマリーを確認
- 学習データおよびテストデータの読み込み
- 誤差関数、最適化器の定義
- 学習
- 結果の可視化
プログラム
必要なライブラリ・モジュール等のインポート
# モデルの定義および学習に使用する
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from tqdm import tqdm # 進捗状況をプログレスバーで表示する
import time
# 学習データの読み込みに使用する
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torchvision
# 学習後の可視化に使用する
import numpy as np
import matplotlib.pyplot as plt
# スプライン補完を使用して滑らかに点を結ぶ
from scipy.interpolate import InterpolatedUnivariateSpline今回は、機械学習ライブラリとしてPyTorchを使用するので、PyTorchからモデルの定義、学習、データセットの読み込みに必要なものをインポートします。最後に正解率の可視化をしますが、その際に滑らかに点を結ぶため、scipyのInterpolatedUnivariateSplineを使用してスプライン補完を行います。ちなみに、今回作成するプログラムはデータ点が少ないため、スプライン補完を使用して滑らかなグラフを描画しますが、より多くのデータ点を取得するなど工夫すればplt.plotを使用するだけで、きれいなグラフが描画できるので、必ず使用しなければいけないというものではありません。
モデルのクラスを定義
PyTorchではkerasに似た書き方もできますが、ここでは、ニューラルネットワークの基本クラスであるtorch.nn.Moduleを継承するサブクラスを定義する方法を使用します。これは、結構便利で、forwardを定義するだけで使用できます。
class Original_LeNet(nn.Module):
def __init__(self, input_image_channels):
super(Original_LeNet, self).__init__()
# チャンネル数input_image_channelsの特徴マップを受け取って、チャンネル数6の特徴マップを出力
self.conv1 = nn.Conv2d(input_image_channels, 6, kernel_size=(5,5), stride=(1, 1))
# チャンネル数6の特徴マップを受け取って、チャンネル数16の特徴マップを出力
self.conv2 = nn.Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
self.max_pool = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # 最大値プーリング
self.bn1 = nn.BatchNorm2d(6) # バッチ正規化
self.bn2 = nn.BatchNorm2d(16) # バッチ正規化
self.fc1 = nn.Linear(5 * 5 * 16, 120) # 線形変換
self.fc2 = nn.Linear(120, 84) # 線形変換
self.fc3 = nn.Linear(84, 10) # 線形変換
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.max_pool(x)
x = F.relu(self.bn2(self.conv2(x)))
x = self.max_pool(x)
x = x.view(-1, 5 * 5 * 16)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # nn.CrossEntropyLoss()を使用するため、log_sftmaxは必要ない
return x モデルのインスタンス化
今回は、GPUを使用して処理を行うため、deviceにCUDAを指定し、インスタンス化します。引数の3は入力特徴マップのチャンネル数(RGB)です。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = Original_LeNet(3).to(device)モデルのサマリーを確認
kerasのmodel.summary()と同じです。これを使用することで、特徴マップの変遷をたどれますし、パラメータの数も確認できます。
# ネットワークの特徴マップの変遷を確認
from torchsummary import summary
summary(net, input_size=(3, 32, 32))サマリーの出力はこんな感じです。
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 456
BatchNorm2d-2 [-1, 6, 28, 28] 12
MaxPool2d-3 [-1, 6, 14, 14] 0
Conv2d-4 [-1, 16, 10, 10] 2,416
BatchNorm2d-5 [-1, 16, 10, 10] 32
MaxPool2d-6 [-1, 16, 5, 5] 0
Linear-7 [-1, 120] 48,120
Linear-8 [-1, 84] 10,164
Linear-9 [-1, 10] 850
================================================================
Total params: 62,050
Trainable params: 62,050
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.36
----------------------------------------------------------------学習データおよびテストデータの読み込み
データの読み込みには、torchvisionを使用します。torchvisionを使用すれば、学習前の煩わしい処理を簡単に終わらせることができます。transformでは、画像データの各チャンネルに対して平均が0.5、標準偏差が0.5になるように指定しています。DataLoaderを使用することで、モデルにバッチでデータを送ることができます。
batch_size=64 # バッチサイズを定義
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = datasets.CIFAR10(root='data', train=True, download=True, transform=transform)
test_set = datasets.CIFAR10(root='data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)誤差関数、最適化器の定義
モデル定義、インスタンス化、学習データの準備ができたら、どのように学習させるかという指針を決定する必要があります。ここではクラス分類なので、交差エントロピー誤差関数を指定しています。そして、最適化器としてはAdamを使用しました。学習率は0.01としています。
loss_fn = nn.CrossEntropyLoss() # 誤差関数を定義
optimizer = optim.Adam(net.parameters(), lr=0.01) # 最適化器を定義学習
それでは学習を行うメソッドを定義して実行します。tqdmを使用して学習の進捗状況をプログレスバーで視覚的に分かるようにしました。
def train(epochs):
acc_his = [0] # 正解率を保持
for epoch in range(epochs):
time.sleep(1)
lpbar = tqdm(train_loader) # プログレスバーを表示する準備
for data, labels in lpbar:
net.train() # ネットワークを学習モードにセット
lpbar.set_description(f"Learning Progress (epoch:{epoch})")
data = data.to(device) # データをGPUへ送る
labels = labels.to(device)
optimizer.zero_grad() # 最適化器の保持する勾配情報をリセット
outputs = net(data) # 出力を求める
loss = loss_fn(outputs, labels) # lossを求める
loss.backward() # バックプロパゲーションの計算
optimizer.step() #パラメータの更新
net.eval() # ネットワークを推論モードにセット
correct = 0 # 正解した数をカウント
with torch.no_grad():
for data, labels in test_loader:
data = data.to(device)
labels = labels.to(device)
outputs = net(data)
_, predicted = torch.max(outputs.data, 1)
correct += (predicted == labels).sum().item()
test_len = len(test_loader.dataset)
acc = 100 * correct / test_len
acc_his.append(acc)
time.sleep(1)
print("accuracy:{:.0f}%\n".format(acc))
return acc_his
hist = train(10)実行結果の可視化
実行結果の可視化は以下のプログラムにより表示させました。データ点が少ないため、スプライン補完を使用して滑らかに結びました。
# 結果の可視化
x = [x for x in range(len(hist))]
y = hist
sp = InterpolatedUnivariateSpline(x, y)
sx = np.linspace(0, 10, 100)
sy = sp(sx)
plt.plot(x, hist[:11], 'o')
plt.plot(sx, sy)
plt.xlabel("epochs")
plt.ylabel("accuracy [%]")
plt.xlim(0, 10)
plt.ylim(0, 100)
plt.grid()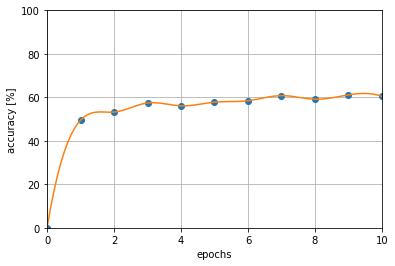
まとめ
結構長い記事になりましたが、畳み込みニューラルネットワークの基本から説明し、理論では簡単な計算式について触れ、コーディングの際に理解が必要な特徴マップに重点を置いて説明しました。そして、最後にはLeNetに似た学習モデルを実装してみました。
ここでは、重要な内容をまとめたいと思います。
- 畳み込みニューラルネットワークの起源はネオコグニトロンで、それを誤差逆伝播で学習できるようにしたものがLeNet。
- 畳み込みニューラルネットワークは局所的受容野と重み共有の2つの特徴により大幅なパラメータ数減少を実現。
- 畳み込み層は特徴抽出、プーリング層は位置ずれ許容を行う。
- 畳み込みニューラルネットワークのプログラミングの際には、特徴マップのチャンネル数を意識する。
かなり内容を削りましたが、こんな感じです。