
本記事は、当サイトのYouTubeチャンネルで公開している動画「[Weekly RL with code]4脚ロボットMinitaurの強化学習」の内容を文字に書き起こしたものです。記載内容は動画と同じです。動画もしくは記事の、お好みの媒体で強化学習について学ぶことができます。
※ Weekly RL with codeは、当サイトがコード付きで強化学習の話題を毎週発信するシリーズです。動画はYouTubeで公開しています。ぜひご覧ください。
今回の内容
みなさんは、Ghost Roboticsの4脚ロボットのMinitaurを知っていますか?もしご存じなければ以下の動画を見ていただければと思いますが、とても単純な構造でありながら、驚くほどの運動能力を実現できる4脚ロボットです。
一般的に、4脚ロボットと聞くと、Boston DynamicsのSpotやUnitree Go1などを想像する方が多いでしょうから、ひょっとしたらご存じなかった方もいるかもしれません。ですが、Minitaurは驚くほど簡単な構造でありながらも、上記動画のような運動性能を持つわけですから、とても興味深いです。
さて、本題に入っていきたいと思いますが、今回はMinitaurのPyBulletのシミュレーション環境について知り、以下の動画のように強化学習で歩行を獲得するところまでを目標に説明していきます。

コードはgoogle colaboratoryで実行します。今回扱ったコードはノードブック形式で公開していますので、ぜひご利用ください。リンクは概要欄に記載の通りです。
公開しているノートブックには、複数のアニメーションと、TensorBoardがセルに表示された状態のもので容量が大きいため、ダウンロードの際は注意してください。重いため、GitHubでプレビューされませんので、一旦ダウンロードしてからGoogle Driveにアップロードしてお使いください。
Minitaur環境
まず最初に、PyBulletのMinitaur環境について簡単に説明します。PyBulletとはロボットのシミュレーションでよく使用される物理エンジンです。PyBulletは、強化学習で最もよく使用される強化学習のインターフェース形式であるGym形式に対応しているので、OpenAI Gymと同じ要領で使用することができます。このPyBulletのGymとしてMinitaur環境は提供されています。
以下はPyBulletのMinitaur環境(以降、Minitaur環境)の最初のフレームを可視化したものです。
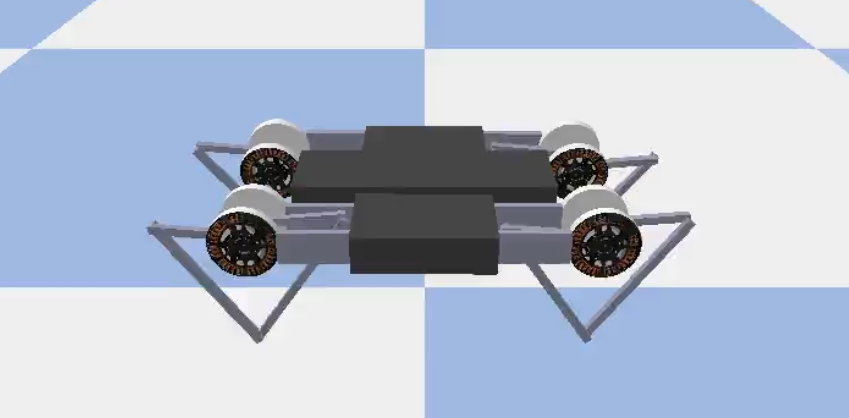
ソースコードを読むとモータの制御情報まで細かくプログラムされているようなので、かなり高精度なシミュレーションが可能であると考えられます。
環境の詳細
それでは、Minitaur環境について詳しく説明していきます。
環境の詳細を調べるときは、状態、行動、報酬、終了条件(+αで初期分布など)を構成するデータは何か、どのような形式で与えらえるかを考えると良いです。これは、強化学習を定式化するときに用いられるマルコフ決定過程の考え方に沿ったもので、強化学習を行う上で大変重要な情報です。マルコフ決定過程と学習環境について詳しく知りたい方は以下の記事を読んでみてください。
状態・行動
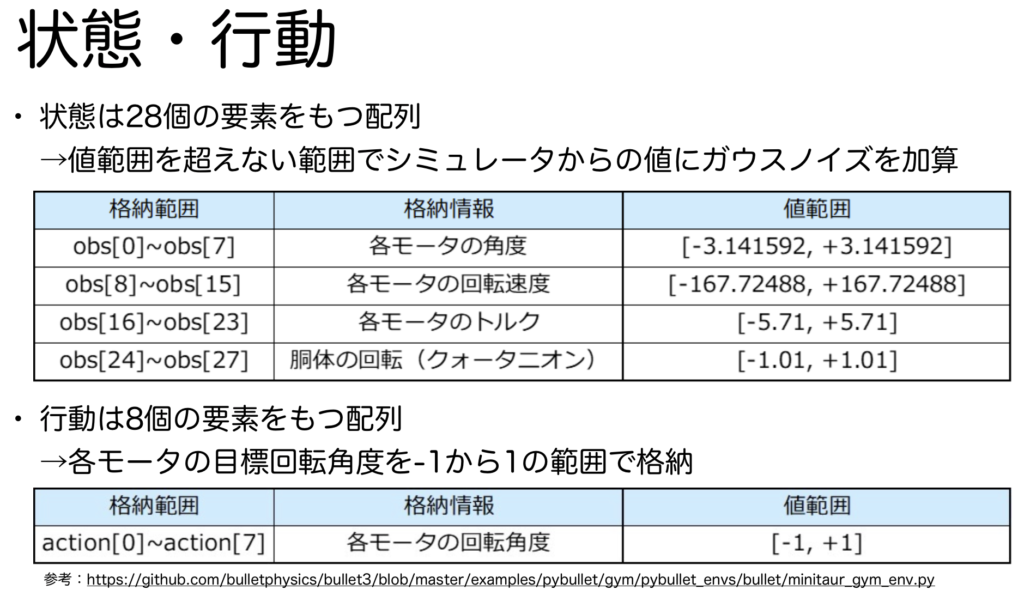
状態・行動は以下の画像の通りです。
状態は、各モータの回転角度、回転速度、トルク、胴体の回転情報を順番に格納した配列です。そして、これらの値にはガウスノイズが加算されており、より現実世界に近くなるように設計されています。図中のobsはobservationの略で観測を意味します。強化学習を行う際の環境は必ずしもマルコフ決定過程として定式化できるとは限らないため、OpenAI Gymでは、マルコフ決定過程の制約を緩めた部分観測決定過程の用語である観測を利用します。
行動は、各モータの目標回転角度を-1から1の間で格納した配列になっています。-1は\(-\pi\)に、1は\(\pi\)に対応します。
報酬
報酬は以下のような計算式により導出されます。報酬は4つの項目から重み和を計算することで導出されるようです。正に作用しるうのは前進報酬(forward_reward)のみで、それ以外はすべて負として作用するようになっているので、ロボットはとにかく\(x\)軸正方向に進むように学習をします。

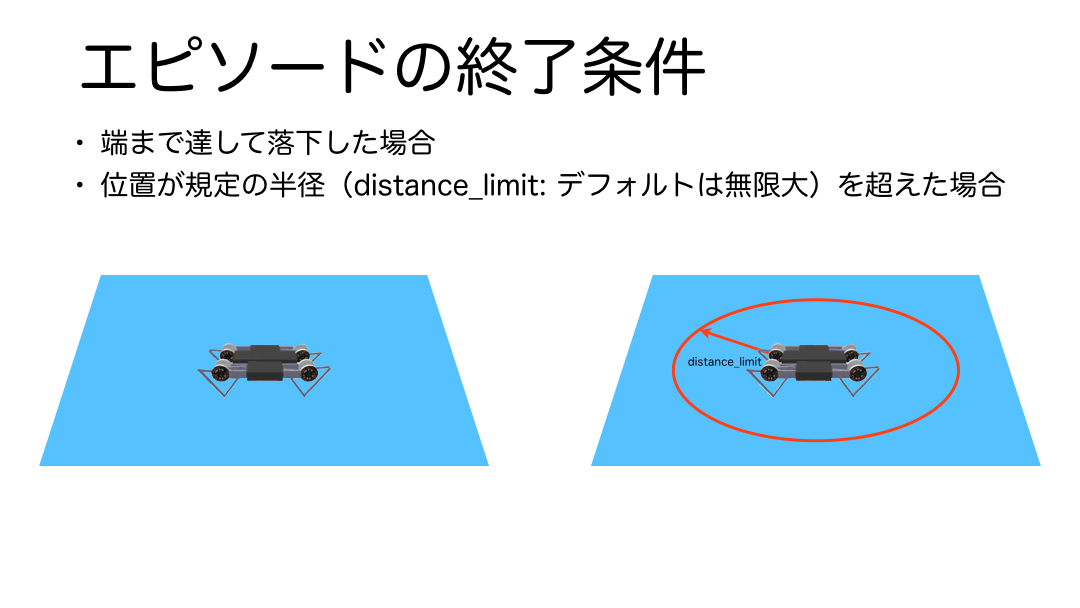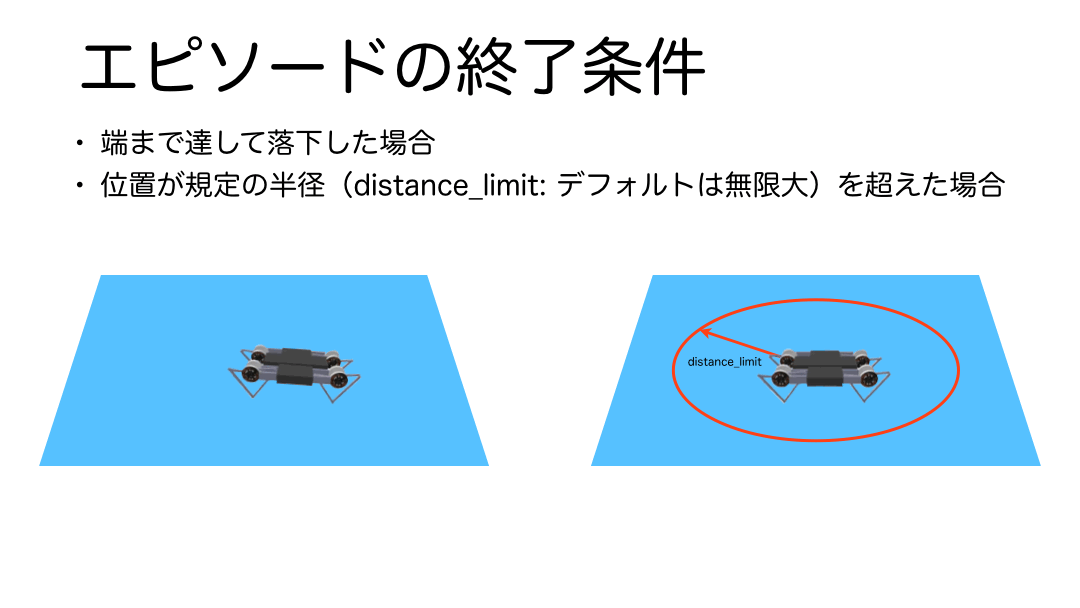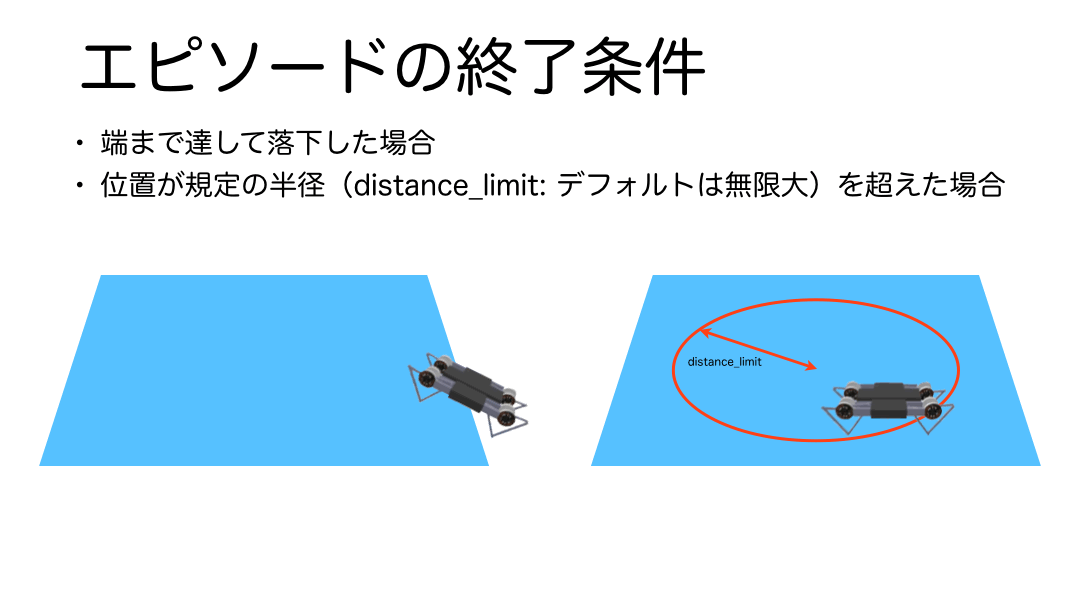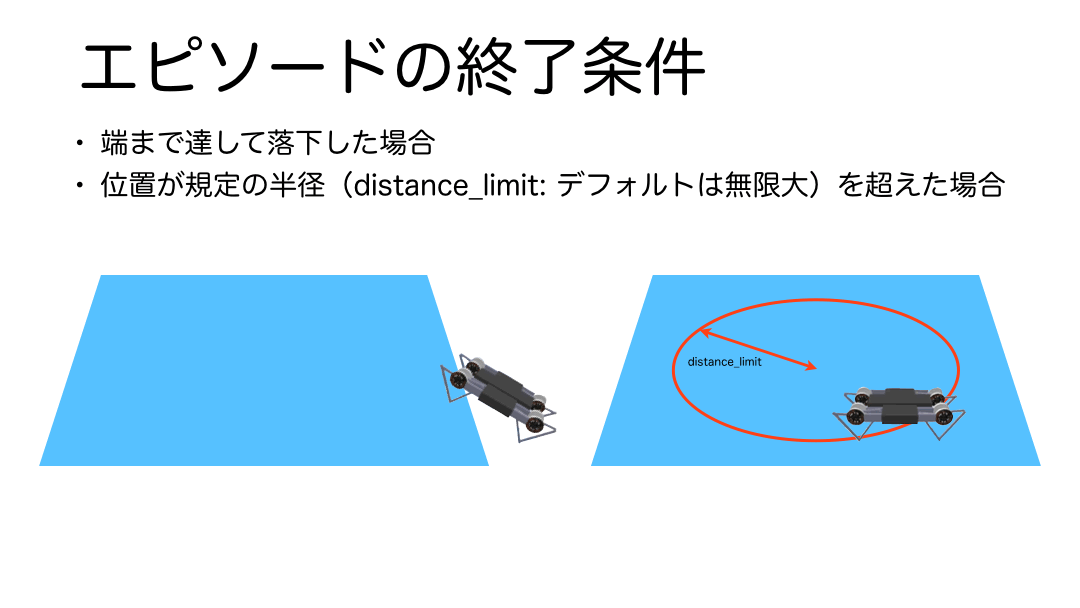
エピソード終了条件
エピソードは学習環境の範囲を超えた場合に終了します。プログラムをみると引数に学習環境の範囲を円の半径で指定するdistance_limitという引数が用意されていることが分かりますが、デフォルトでは値が無限大なので、その場合は学習環境の床の範囲外へ到達した場合、もしdistance_limitが指定されていた場合は、その縁の淵に到達した場合にエピソードが終了するようになっています。
強化学習問題
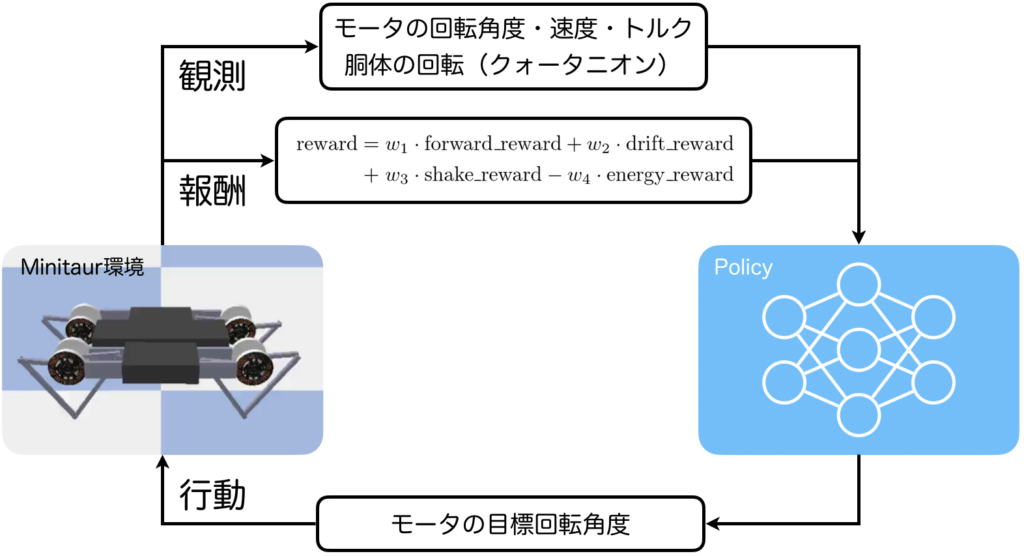
ここまで説明してきた内容を強化学習問題として図式化すると以下のようになります。左が環境で右がエージェント(強化学習アルゴリズムの方策)です。環境からエージェントへは、観測(状態)として、各モータの回転角度・回転速度・トルク、胴体の回転が与えられ、エージェントから環境へは各モータの目標回転角度が与えられます。これらの観測と行動から報酬が計算されます。
コードの実行
Google Colab形式のコードはここで公開していますので、ぜひご利用ください!
準備
まずはMinitaur環境を使えるようにします。また、強化学習ライブラリとしてStable Baselines3を使用します。以下のコードを実行して下さい。
!apt-get update
!apt-get install -y xvfb ffmpeg
!pip install imageio # 2.4.0 ?
!pip install matplotlib
!pip install pybullet
!pip install stable-baselines3
!pip install sb3-contrib
!pip install tensorboard
!pip install pyglet==1.5.27
!git clone https://github.com/aakmsk/gymvideo.gitインストールが済んだら、必要なものをインポートします。
import gym
import pybullet_envs.bullet.minitaur_gym_env as e
from stable_baselines3.common.env_checker import check_env
from stable_baselines3 import PPO, SAC
from sb3_contrib import TQC
from gymvideo.scripts.gymvideo import GymVideo次に、環境をインスタンス化します。
# 環境のインスタンス化とリセット
env = e.MinitaurBulletEnv()
env = GymVideo(env)
env.reset()また、以下も忘れずに実行しておきましょう。
# Gifアニメーションの保存先フォルダを作成
!mkdir Gif
gif_dir = "Gif/"
# TensoBoard用
logs_base_dir = "TensorBoard/"
total_timesteps = 1000000 # 100万PPO
以下のコードを実行してください。
%%capture
ppo_model = PPO("MlpPolicy", env, verbose=1, tensorboard_log=logs_base_dir)
ppo_model.learn(total_timesteps=total_timesteps)学習が終わったら可視化してみましょう。
env.execute_one_episode(ppo_model)
env.save_video(save_name=gif_dir+"ppo_minitaur.gif")SAC
以下のコードを実行してください。
%%capture
sac_model = SAC("MlpPolicy", env, verbose=1, tensorboard_log=logs_base_dir)
sac_model.learn(total_timesteps=total_timesteps)学習が終わったら可視化してみましょう。
env.execute_one_episode(sac_model)
env.save_video(save_name=gif_dir+"sac_minitaur.gif")SACは個人的にはかなり驚きました。割と自然な4脚歩行を獲得しているのではないでしょうか?4脚ロボットの歩き方(歩容)には様々ありますが、トロットと呼ばれる歩容に最も近いように思います。トロットを獲得するように仕向けるような報酬ではないので、自然にトロットが獲得されたというてんはとても興味深いと思います。
TQC
以下のコードを実行してください。
%%capture
tqc_model = TQC("MlpPolicy", env, verbose=1, tensorboard_log=logs_base_dir)
tqc_model.learn(total_timesteps=total_timesteps)学習が終わったら可視化してみましょう。
env.execute_one_episode(tqc_model)
env.save_video(save_name=gif_dir+"tqc_minitaur.gif")#, display_inline=True)前回の記事では、TQCはとてもよい成果を出してくれたので、今回も試したのですが、結果としては結構残念なかたちになりました。
前回の記事↓

報酬の移り変わり
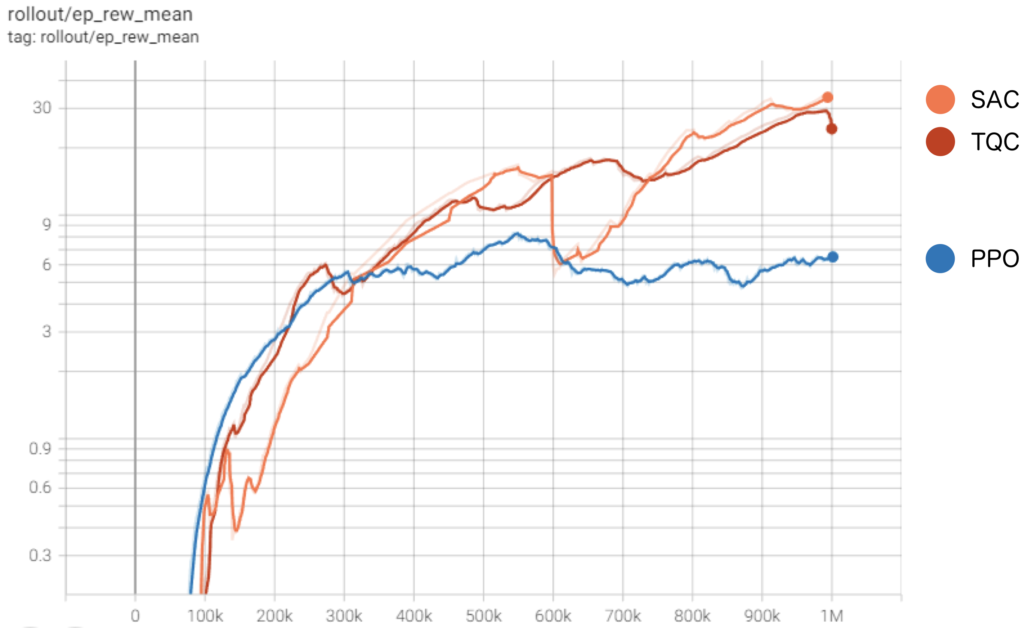
それぞれのアルゴリズムにおいて、得られた報酬の移り変わりを可視化してみました。SACが得ている報酬が最も高いのは分かりますが、TQCも高いのは結構謎です。SACとほぼ変わらない報酬を得ているなら、同じくらいの歩行を見せてくれてもよいと思うんですが、、、。何回試してもダメでした。少し調査してみようと思います。何かわかり次第、記事に追記します。
まとめ
今回は、Minitaur環境について環境の詳細と使い方を説明し、強化学習を実行してみました。
歩行というと、結構獲得が難しそうなイメージがあしましたが、意外にも簡単に学習できることが分かりました。
今後、報酬の計算式をかえてみたりすることで、より自然な歩行獲得を目指した実験を試してみたいと思います。
最後までお読みいただきありがとうございました。