
本記事では、R-CNN(Regions with CNN features)について解説していきます。
要点
要点として、R-CNNが提案された当時の背景と、R-CNNで解決されたこと、つまり新規性、そして、実績の3つについて紹介します。
- 背景
- R-CNNが提案された当時、PASCAL VOCの物体検出(object detection)の性能が頭打ちに。
- 精度を上げるため、複雑なアンサンブルによる検出モデルも現れた。
- 新規性
- 単純で柔軟な新しい検出アルゴリズムを提案(=R-CNN)。
- 実績
- PASCAL VOC 2012において、前回のmAPの最高値を30%も超える、53.3%を達成。
- 同じCNNを使いつつも、R-CNNとは異なるスライディングウィンドウ方式を採用したOverFeatという検出器と比較して、ILSVRC2013の物体検出では、R-CNNのmAPが31.4%、OverFeatのmAPが24.3%となり大差で勝利。
R-CNNのアーキテクチャ
この章では、R-CNNのアーキテクチャについて解説します。まず、概略を先に示します。R-CNNは、主に3つのステップからなっていて、画像が入力されたらステップ1でカテゴリに依存せず、何かしら検出可能と予想される領域を約2000個ほど提案します。ステップ2はCNNを使用して、画像特徴を固定長の特徴ベクトルに変換します。ステップ3では、その特徴ベクトルの所属するクラスを特定します。

オリジナルのR-CNNでは、ステップ1の領域提案(Region proposal)にSelective Searchが、ステップ2のCNNにAlexNetが、ステップ3のクラス分類に線形SVMのセットが使用されています。
現在は、領域提案からクラス分類までEnd-to-Endで実現しますが、R-CNNが提案された当時は、CNNが注目され始めたばかりであることと、古典的な手法の名残が残っている影響か、Step1とStep3では古風な手法となっています。
ステップ1:Selective Search
ステップ1では、検出可能な何かが映っていると予測される領域を選定する操作を行います。すなわち、R-CNNではスライディングウィンドウ方式のようにすべての領域をCNNに渡すことはせず、検出可能な何かが映っていると予測される部分にのみCNNで特徴ベクトルへ変換することで、無駄な計算を減らそうという戦略です。
ステップ1で行う作業のイメージを説明します。以下の図において、左側が物体検出したい画像だとします。この際、全てのサイズ、領域において、スライディングウィンドウ方式で実行すると大変ですので、右のように、ある程度候補となる領域を絞り込みたいですよね。領域を絞り込むときは、映っているものが何かは関係ありませんので、万が一、検出可能な対象以外が絞り出されてしまっても問題ありません。とにかく、CNNへ渡す部分にあたりをつけます。
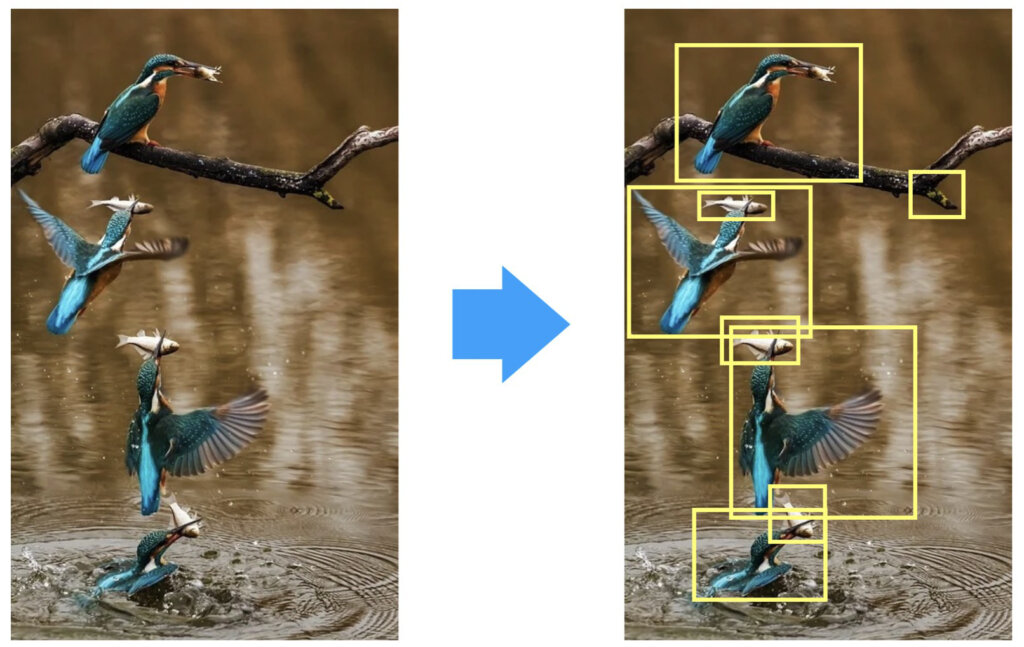
ここで、「検出可能な何か」をどのように認識するかですが、その方法は様々あり、R-CNNでは、Selective Searchと呼ばれる手法を採用しました。ここでは、Selective Searchについての詳しい解説はしませんが、興味がある方は検索してみてください。
ステップ2:CNN
ステップ2では、ステップ1で提案された領域をCNNで固定長の特徴ベクトルへ変換します。論文で紹介されたR-CNNでは、CNNとして、ILSVRC2012で優勝したAlexNetと呼ばれるモデルが採用されました。AlexNetは以下の図に示すように、大まかに5つの畳み込み層と3つの全結合層からなっています。3つの全結合層のうち最後のsoftmax層は識別層なので、R-CNNではsoftmax層を取り除いた、5つの畳み込み層+2つの全結合層の部分を使用し、Selective Searchで提案された領域の画像を4096次元の特徴ベクトルに変換します。
※AlexNetでは2つのGPUで計算するために、構造的に2パスに分かれています。また、論文発表当時はAlexNetがブームでしたので、R-CNNで採用されたものと思われますが、現在ではより高性能なCNNが沢山あります。
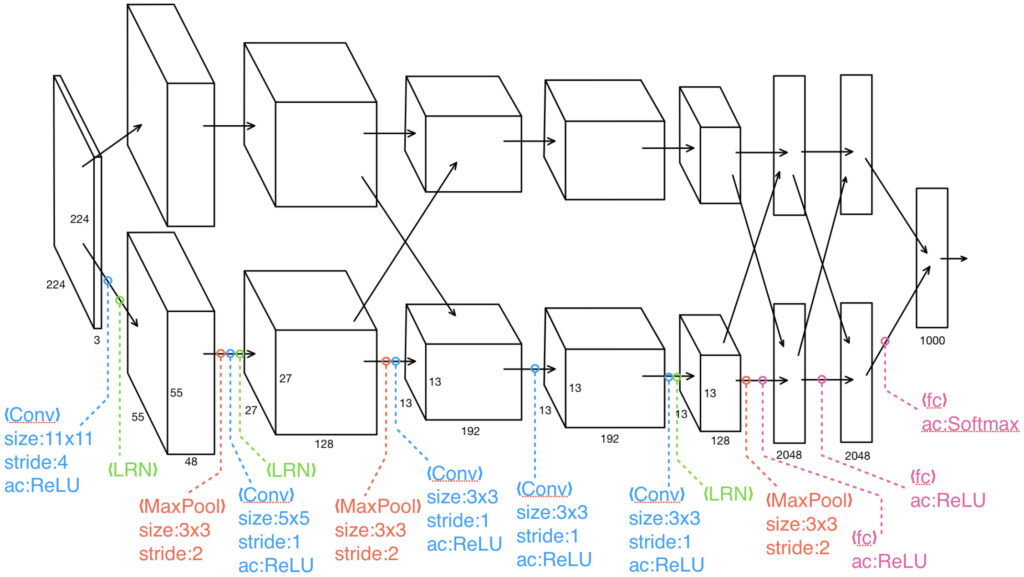
上図において、入力サイズが224x224x3となっていますが、実際は227x227x3です。余計混乱することを言いましたが、AlexNetに入力したい画像は224x224x3で、実際にAlexNetに入力する際は、ゼロパディングして227x227x3にするらしいです。私も詳しく知らないですが、あーなるほどという感じです。なので、以降では227x227x3で話を進めることにします。
これから説明するのは、ステップ1のSelective Searchからステップ2のCNNに情報が渡される際にどのような作業が行われるかについてです。Selective Searchで提案された領域は、きれいに227x227の可能性もありますが、大抵はそうじゃなくて、サイズが合わなかったり、形が合わなかったりするのが普通です。しかし、AlexNetは227x227のサイズしか受け取りません。これでは、ステップ1とステップ2繋げることができません。そのため、提案された領域の画像を227x227に変換する必要があります。変換する方法として様々思いつきますが、R-CNNでは、強引に227x227に変更する方法を採用しています。つまり、例として以下の画像に示したように、長方形で提案された領域が横方向にグッと押しつぶされるような操作が行われるわけです。

このようにすることで、とりあえずはステップ1とステップ2を繋げることができました。
ステップ3:クラス固有の線形SVM
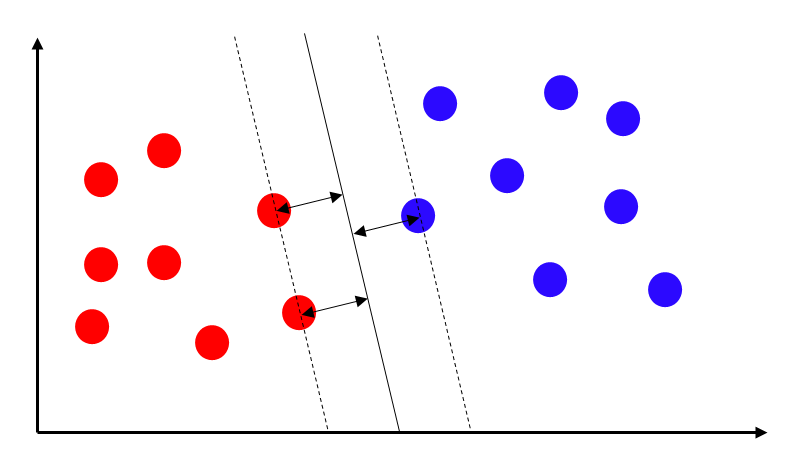
ステップ3では、それぞれのクラス用にトレーニングされた固有の線形SVMのセットを使って、特徴ベクトルを分類することで、画像の特定領域のクラスを得ます。最も単純な線形SVMを以下に示します。認識したいクラス数分のSVMを用意し、それぞれのSVMの学習は認識したいクラスかそれ以外かの分類問題に帰着させることで対応が可能です。
R-CNNの学習
R-CNNの学習は、ステップ2のCNN部分とステップ3のSVM部分になります。順番に解説していきます。
CNNの学習
先ほど、CNNとしてAlexNetを使用することと、softmax層は使用しないことを説明しましたが、学習時にはsoftmax層を使用します。オリジナルなR-CNNではCNNを以下の2フェーズに分けて学習を行います。順番に解説していきます。
教師あり事前学習
まず最初に教師あり事前学習を行います。事前学習とは言いますが、ここで行っているのはクラス分類タスクが行えるようにCNNを学習させることです。ILSVRC2012のクラス分類で使用したデータセットを使用して学習を行います。つまり、softmax層が存在する状態で1000クラス分類を学習させます。
ドメイン固有のファインチューニング
この作業は、主に2つの理由により実施されます。1つ目は、Selective Searchで提案された様々なサイズの領域画像をAlexNetに入力する際に227x227のサイズへ強引に変換することに起因した画像の変形により識別性能が低下すること、2つ目は、物体検知で識別したいクラス数\(N\)は必ずしも1000ではないことと同時に、背景クラスを1つ追加した、\(N+1\)クラス分類のタスクとしてモデルを利用したいためです。ちなみに、PASCAL VOCにおける物体検出では20クラス、ILSVRC2013の物体検出では200クラスです。
物体検出では、バウンディングボックスを使用して、領域を示しますが、どのバウンディングボックスが正しいのか、もしくは間違っているのかという情報が、学習に必要になります。そこで、バウンディングボックスで示された領域に、識別したいクラスの物体が映っているか、映っていない(=背景と解釈可)かを論理的に決定する必要があります。そこで使用されるのが、IoUです。IoUについては補足として最後に説明していますので、気になる方は補足を参照ください。
線形SVMの学習
ここでは、線形SVMによる認識対象クラスかそれ以外かという二項分類問題を考えます。
CNNから出力された特徴量を線形SVMの入力、その特徴量の元の画像領域が正解画像領域とどのくらい重なっているかを示すIoU値とその閾値と比較して導出される真偽を教師信号として学習させます。
補足
IoUとは
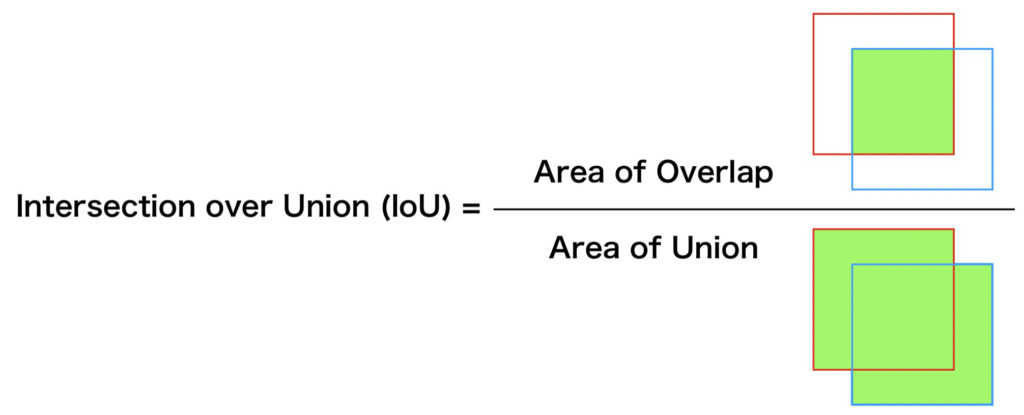
物体検出においては、物体認識タスクより難度が高く、検出対象が映っている場所をバウンディングボックスなどで正しく示せる必要があります。そこで、教師となる正しいバウンディングボックスとモデルが示したバウンディングボックスを使って、モデルが示した位置がどの程度正しいか判断するための指標が必要になります。この指標がIoU(Intersection of Union)です。IoUは正解領域とモデルの出力した領域において重なった部分を、両者を合わせた領域で割ることで求まります。そのため、モデルから出力された領域が正解領域と全く重ならない場合は0に、ぴったり重なる場合は1になります。物体認識のように、あたりorはずれの2択ではなく、[0, 1]の連続値となります。
IoUが連続値になるとは言いつつも、IoUがある値より大きければTrue、小さければFalseといった使い方をすることが一般的です。
mAPとは
mAP(mean Average Precision)について丁寧に解説すると、別途記事が必要になりそうなので、ここでは簡易的に済ませたいと思います。
上で示したようにしてIoUが求まるとします。このとき、ある閾値を決め、IoUが閾値より大きいか小さいかを比較することで、真偽判定をすることができます。真偽判定ができれば、適合率(Precision)と再現率(Recall)を求めることができ、PR曲線が描けます。あとは、PrecisionをRecallで積分することで、平均適合率(Average Precision;AP)が求まります。APが求まれば、最後にすべてのクラスに対して平均を計算すればmAPを求めることができます。
まとめ
R-CNNは現在の物体検出の原点だと個人的に思っていますが、今は、R-CNNの改良を重ねて大きな精度向上を実現しています。R-CNNのアーキテクチャを学ぶことが、現在の物体検出を学ぶために重要かといわれると微妙なところではあると思いますが、先駆者たちのアイディア、解決プロセス等々、学べる点がいくつもあると考えています。
個人的に、物体検出について学ぶのは、ほぼ初めてだったので、大変勉強になりました。
最後までお読みいただきありがとうございます。
参考文献
R. Girshick, J. Donahue, T. Darrell, J. Malik. "Rich feature hierarchies for accurate object detection and semantic segmentation", arXiv:1311.2524