
本記事では、DeepMindが2022年に公開した、単一の大規模モデルで画像のキャプショニングやチャット、ロボット制御など600を超えるタスクを行うことができる汎用エージェントのGatoについて解説します。Gatoの登場により汎用人工知能はTransformerを用いたGPTアーキテクチャの延長で実現できる可能性が示唆されました。
本記事では、Gatoについて私なりに理解したことを記載していきます。
概要
Gato[1]とは、DeepMindが2022年に公開した、GPTアーキテクチャをベースとする単一のモデルで画像のキャプショニングやチャット、ロボット制御など600を超えるタスクを実行できる汎用エージェント(Generalist Agent)のことです。Gatoはデータ駆動型強化学習、いわゆるオフライン強化学習手法によるエージェントであり、オフライン強化学習をTransformerを用いたGPTアーキテクチャで実現したDecision Transformerの延長線上にあると考えることができます。Decision Transformerにより、Transformerを用いた強化学習エージェントはスケーリング則を適用することができ、モデルサイズなどの向上により性能向上が見込まれることが示されたため、同時に複数のタスクを学習させることも可能なのではないかという発想であると解釈することができるでしょう。
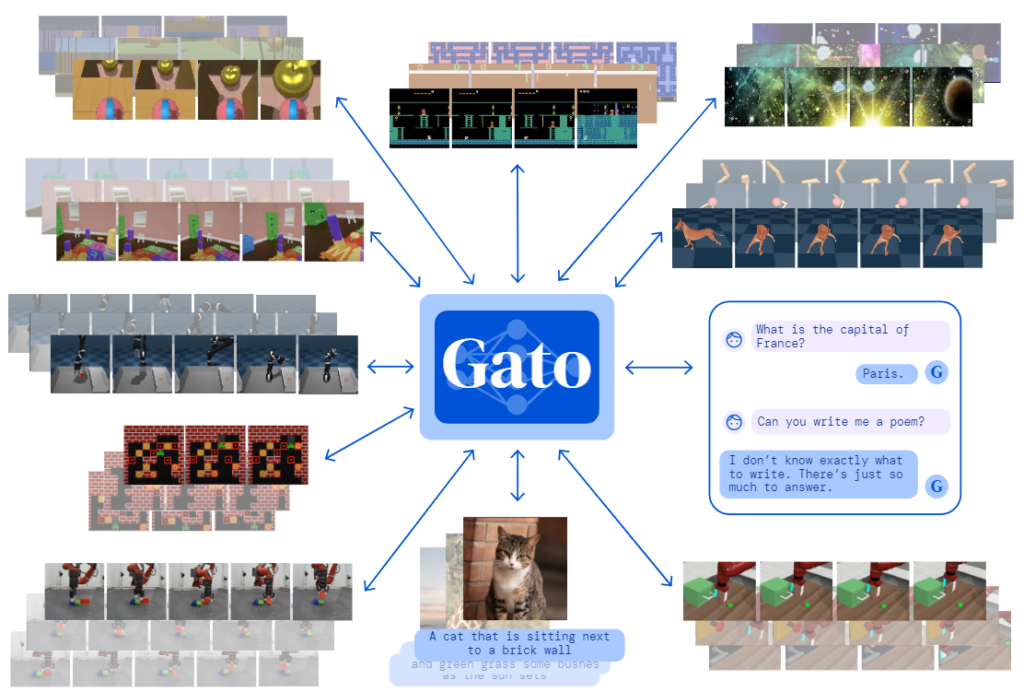
また、Gatoでは複数のタスクを単一モデルで実行するために、プロンプトによる出力の条件付けという考え方が採用されました。今でこそ、Stable DiffusionやChatGPTなどの普及により、プロンプトというワードが有名となっていますが、タスクをプロンプトで条件付けるというのは最近登場した手法であり、Gatoはそれが取り入れられた代表的な手法の1つです。
それでは、順を追ってこれらの内容を説明していきます。
Decision Transformer
Gatoが登場する以前に、オフライン強化学習を系列問題として扱いTransformerを用いたGPTアーキテクチャで実現した手法にDecision Transformerがあります。Decision Transformerは、AtariやOpenAI Gym、Key-To-Doorなどをはじめ、多数のモデルフリーのオフライン強化学習タスクにおいてベールラインと同等か、それ以上の性能を達成することができたモデルです。
Transformerというと、自然言語処理をはじめ、多種多様な領域で大きな成果をあげているニューラルネットワークのアーキテクチャですから、それを深層強化学習の方策ネットワークに用いた研究なのかな?と思われるかもしれませんが、そうではありません。Decision Transformerでは、強化学習を系列問題として解きます。他の強化学習手法は価値の最大化問題として方策獲得を目指しますが、Decision Transformerではそれを踏襲していないため、それらの概念は不必要となっています。
強化学習について勉強したことがある方であれば、そのゴリゴリの数学で理解が難しい分野の上に成り立っているものであることはご理解いただけると思いますが、Decision Transformerはそれを崩すような衝撃的なものでした。
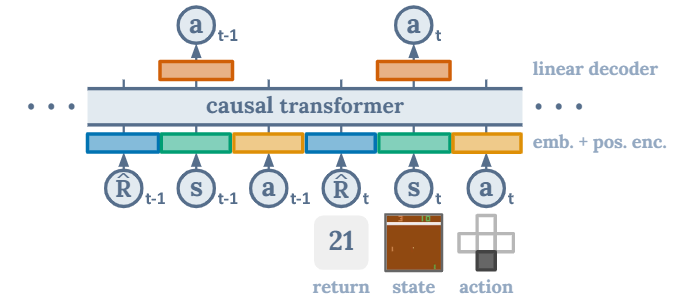
処理について簡単に紹介すると、扱う系列データを以下のように定義します。
$$
\tau = \{\hat{R}_1, s_1, a_1, \cdots,\hat{R}_{t-1}, s_{t-1}, a_{t-1},\hat{R}_t, s_t, a_t ,\cdots, \hat{R}_T, s_T, a_T\}
$$
$$
\hat{R}_t = \sum_{t'=t}^T r_{t'}
$$
Decision Transformerの入力は報酬・状態・行動、出力は行動です。報酬はスカラー、状態や行動はベクトルであり、扱うデータは画像やモータの角度など多種多様です。その為、報酬・状態・行動ごとに別々の埋め込み層を適用しTransformerへ入力できるベクトルへサイズへと変換します。そして、位置埋め込みベクトルを足し合わせたものをTransformerへの入力とします。
学習では\(\tau\)を入力して、\(\{⋯,a_{t−1},a_t,⋯\}\)を出力するようにパラメータを最適化します。ただし、先読みを防止するため、\(a_t\)を予測するときは、\(\{\hat{R}_1,s_1,a_1,⋯,\hat{R}_{t−1},s_{t−1},a_{t−1},\hat{R}_t,s_t\}\)のみを使用するようにマスク操作をします。
ようするに、状態から行動へのマッピングを即時報酬で条件付けた表現を学習するのです。これには、強力な関数近似器が必要ですが、Transformerであれば、高い精度で実現できます。この仕組みが十分に既存手法と同等かそれ以上のレベルを達成できることを示したのがDecision Transformerです。
詳細は以下の記事で説明しているので、気になる方はご参考ください。

Gatoはこの考え方を踏襲しており、オフライン強化学習タスクを系列問題として扱い、Transformerで学習される方法を採用しています。
しかし、Gatoでは、600を超える多くのタスクを扱うため、報酬だけで行動を条件付けするのが難しくなりました。そこで、報酬を学習に用いることをやめ、タスクの初めの系列をプロンプトとして入力し、以降の行動を条件付けする方法を採用するようになりました。
プロンプトによる条件付け
それでは、Gatoの大きな工夫であるプロンプトによる条件付けについて説明します。
ChatGPTが登場して以降、得たい出力が得られるようにプロンプトを工夫するプロンプトエンジニアリングが流行っています。しかし、なぜプロンプトで出力を調節することができるのでしょうか?別の言い方をすれば、なぜプロンプトで出力を条件付けることができるのでしょうか?
ここでは、そのような内容を簡単に説明します。まず、プロンプトで出力を条件付けるという考え方は、最近登場した新しい手法です。プロンプトによる条件付けは、報酬のような数値的な条件付けよりも細かな条件付けが可能で、例えば言葉の微妙なニュアンスの違いを出力に反映させることができます。Gatoではこのようなプロンプトによる条件付けが採用されました。条件付けが報酬ではなくプロンプトに変わったことで、私たち人間にとっても機械学習への指示が出しやすくなりました。例えば、エキスパートのような行動を出力して欲しいときは、エキスパートならこうするだろうと考えられる系列の初めを入力してあげれば、続きを作成してくれるのです。
Gatoでは、学習に使用する系列データの25%をプロンプトとして設定しています。
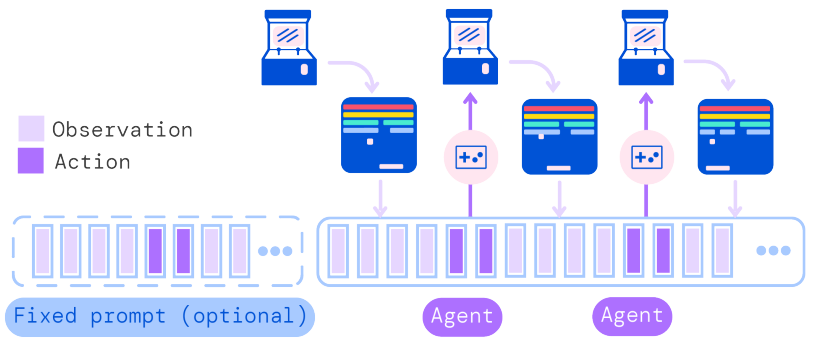
オフライン強化学習はデータセットから学習するという点で教師ありによる系列データの学習と似ていますが、あくまでも強化学習であるため行動出力に報酬が絡んでいました。しかし、報酬による条件付けからプロンプトによる条件付けに変わったことで、教師ありによる系列データの学習と実質的にはあまり変わらなくなりました。
そのため、Gatoでは言語生成のような強化学習を用いないようなタスクと、ロボットの動作学習のような強化学習を必要とするタスクを同時に扱うことが可能になりました。
仕組み
Gatoの仕組みはとても単純です。各モダリティを専用の埋め込み関数を用いて、統一された次元の埋め込みベクトルに変換し、それらを並べて作られた系列データを言語モデルと同じ考え方で学習しています。学習ではバッチ学習を使用していますが、単一種類のタスクのデータのバッチ学習ではなく、複数種類のタスクのデータがごちゃまぜにされたもののバッチ学習を行います。
Gatoの仕組みを詳しく知るには、モダリティごとの具体的なトークン化、埋め込み処理、系列モデル(Gato本体)、損失関数の4つを知る必要があります。これらについては以降で詳しく説明していきます。
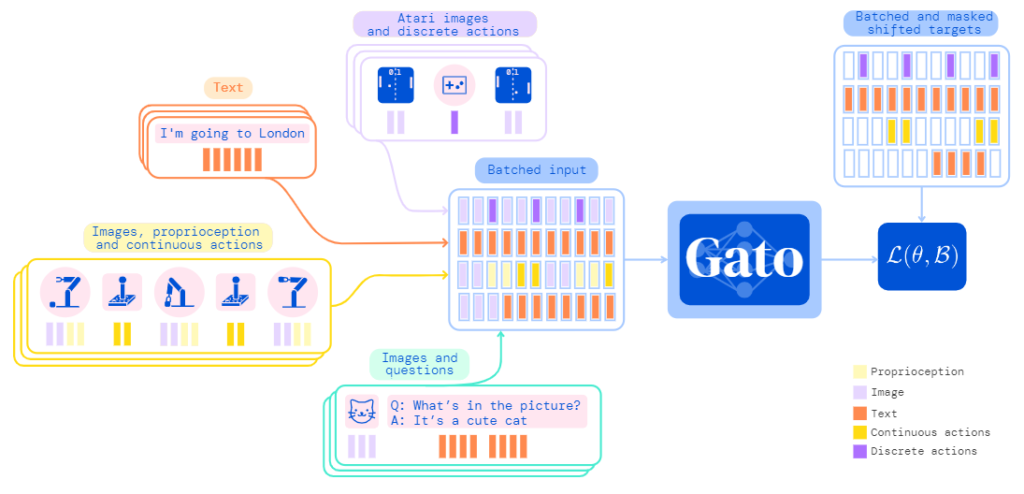
ここでは、下図を用いてざっくりとGatoの仕組みの全体像を把握しましょう。図の左側には、具体的な4つのタスクが記載されています。
① 入力:Atariのゲーム画面
出力:離散値
② 入力:テキスト
出力、テキスト
③ 入力:画像、ロボットの位置、姿勢など
出力:連続値出力(ロボットの関節角度)
④ 入力:画像、テキスト
出力:テキスト
扱っているモダリティはテキストだけでなく、画像や離散値、連続値と多種多様です。これらを単一の系列モデルで扱うには、同一サイズのベクトルで表現してあげる必要があります。Gatoでは、そのための手法を埋め込み関数と呼び、それを適用して統一されたサイズのベクトル系列に変換されます。図の中ほどにあるBatched Inputには4つのタスクが並列に並べられていることが分かります。つまり、Gatoでは複数のタスクを同時に処理することが求められているのです。そして、系列モデルではそれらを言語モデルと同様の考え方に基づき学習を行います。後でも説明しますが、バッチデータの中に異なるタスクが複数含まれた状態で学習できるよう、特殊な損失関数\(\mathcal{L}(\theta, \mathcal{B})\)が使用されています。
系列モデルとして使われているモデルはTransformerを用いたGPTアーキテクチャです。
トークン化
トークンとは、機械学習分野だと自然言語処理で最もよく使われるワードで、処理単位に分解することを意味します。例えば、文章「This is my robot.」を単語毎に「this」、「is」、「my」、「robot」、「.」のように分割する処理を意味します。また同時に、単語の番号に変換されることがあります。今回のGatoでは、テキスト以外に、画像や離散値、連続値も扱います。これらはどのようなルールに則ってトークン化しているのでしょうか。概要を下の表に示します。
| テキスト | SentencePieceを用いて[0,32000)の範囲に変換した整数値 |
| 画像 | オーバーラップなしの16x16のパッチに分割したときの各パッチ |
| 離散値 | [0,1024)の整数値 |
| 連続値 | 1024個のビンで離散化され該当範囲の番号を32000だけシフトさせた[32000, 33024)の整数値 |
順番に具体的な処理についてみていきましょう。
テキストはSentencePieceと呼ばれる手法を用いて[0,32000)の範囲の整数値に変換されます。また、最終的には入力されたテキストの順番に沿って整数値が並べられた系列データになります。

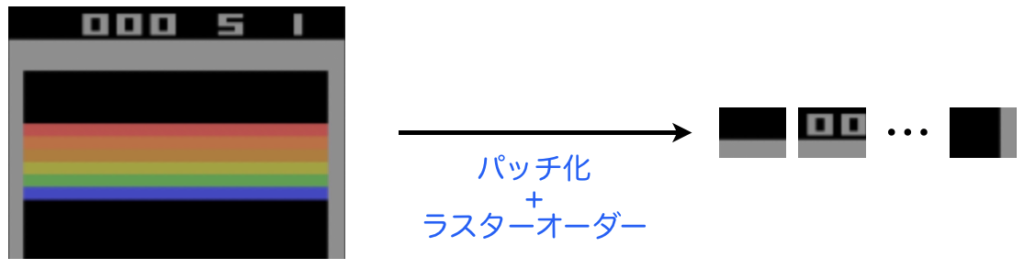
画像はオーバーラップなしの16x16のパッチに分割されたときのパッチをトークンの単位とします。画像パッチトークンとも呼ばれます。そして、これは16x16=256個のパッチができるため、それらをラスターオーダーで並べたものを画像の系列データとします。
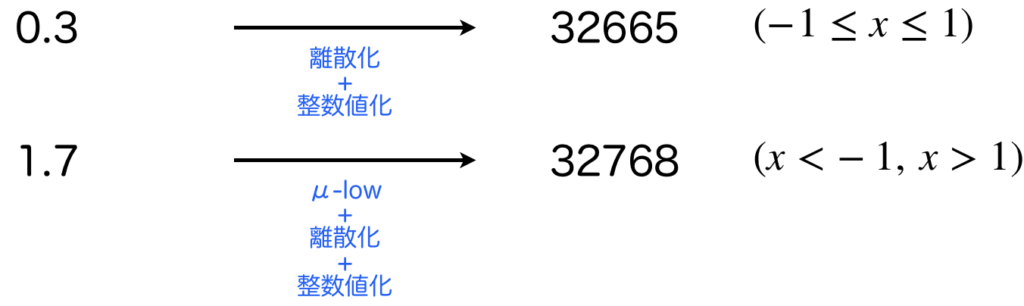
離散値ですが、これはOpenAI Gym形式の強化学習環境を知っている方であればわかると思いますが、Discrete型は既に整数による離散値になっているため、そのまま扱います。値範囲は[0, 1024)とします(図は省略)。
連続値は扱いが少し複雑です。Gatoでは[-1,1]の範囲の連続値のみを受け付け、その範囲を1024個のビンで量子化しトークンに変換する操作を行います。そのため、変換したい連続値の生データが[-1,1]に収まっていれば、そのまま量子化します。一方で、1.7や4.6みたいに範囲外の場合は、[-1,1]の範囲に収まるようにμ-lowを用いて値を変換します。
μ-lowについて
μ-lowについて補足します。μ-lowとは対数を用いて信号のダイナミックレンジを低減させるコンパンディングアルゴリズムです。私たちは会話するときのような身近な音量であれば僅かな音の大小を感じることができますが、大音量の場合は大小を感じにくいという特性があります。つまり、認識の細かさは非線形で、普段使用する領域の分解能は高く、そうでない領域は低くなるようにすることで幅広い入力に対応できるようにしているといえます。この機能をアナログからデジタルへ変換するときの量子化において実現するためによく使われるのがμ-lowです。
Gatoで用いたμ-lowの式は以下の通りです。
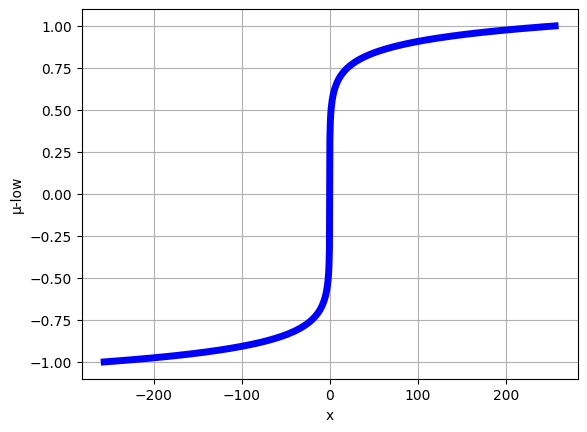
$$
F(x) = \text{sgn} (x)\frac{\log (|x|\mu + 1.0)}{\log (M\mu + 1.0)}
$$
(\mu=100, M=256)としています。これをグラフにすると以下のようになります。これを縦軸で量子化することを考えると、(x)の値が0に近い領域における量子化誤差は小さく、それ以外の領域の入力の量子化誤差は大きくなります。
上のグラフを生成するプログラムは以下の通りです。
import numpy as np
import matplotlib.pyplot as plt
def F(x, mu, M):
return np.sign(x) * np.log(np.abs(x) * mu + 1.0) / np.log(M * mu + 1.0)
x = np.linspace(-256,256, 1000)
y = F(x, 100, 256)
plt.plot(x, y, linewidth=5, color='b')
plt.grid()
plt.xlabel("x")
plt.ylabel("μ-low")以上より、テキスト、画像、離散値、連続値を、整数値もしくは画像パッチのトークンで表現することができました。
埋め込み処理
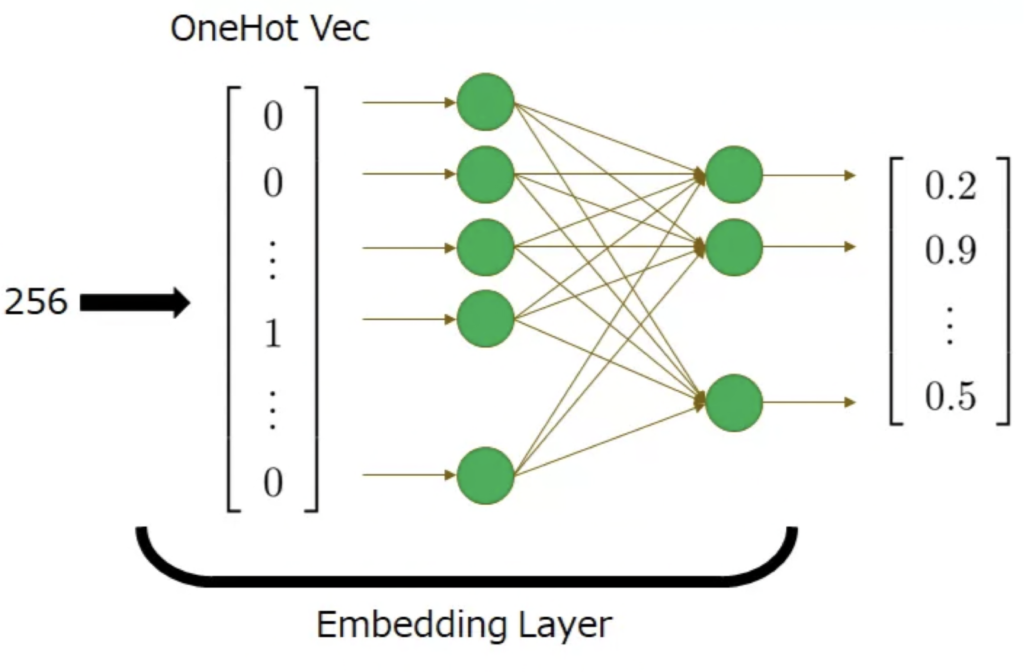
埋め込み処理では、上でトークン化したものを埋め込みベクトルに変換します。具体的に、整数値については単語の埋め込み層とおなじく線形埋め込み層を用いて埋め込みベクトルへと変換します。画像パッチについてはResNetで使われるResidual Blockを用いてベクトルへ変換します。
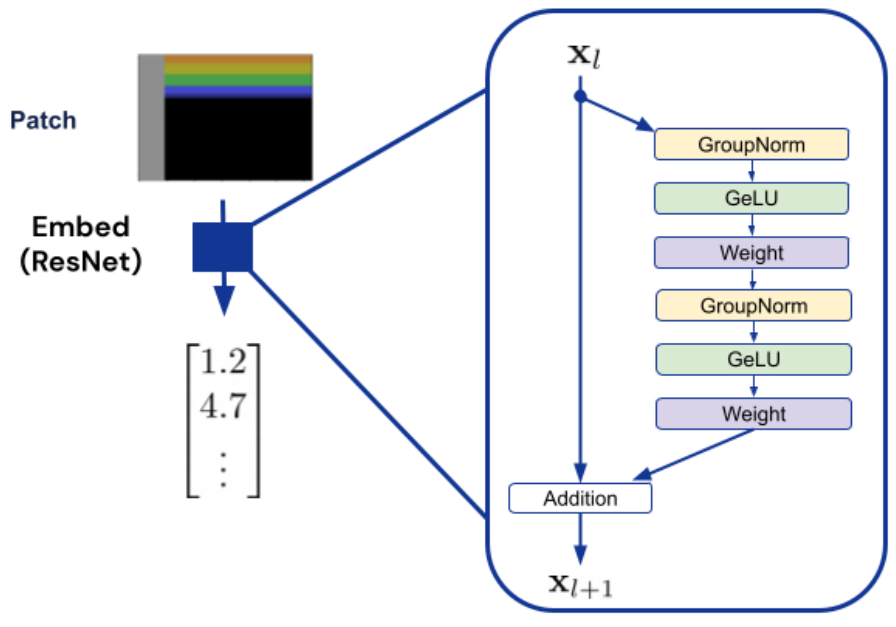
具体例
それでは、トークン化と埋め込み処理の具体例を通じて理解を深めましょう。ここでは2つの具体例を紹介します。
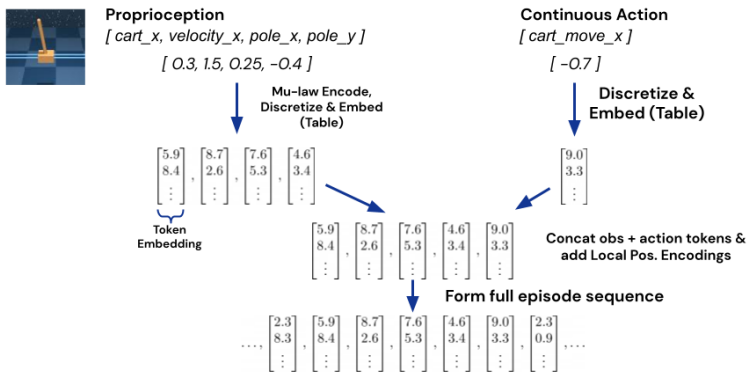
1つ目はCartPoleの例です。CartPoleの観測は[cart_x, velocity_y, pole_x, pole_y]、行動は[cart_move_x]です。これらは両方とも連続値で、観測は[-1,1]の範囲外になる可能性があり、行動はその範囲内に収まるものとします。詳細は学習タスクにより異なりますが、OpenAI Gym形式であれば、環境の出力範囲はobservation_space、出力範囲はaction_spaceで確認することができます。
Gatoは[-1,1]の範囲の連続値しか受け付けない仕様であるため、範囲外になる可能性がある場合はμ-lowを用いて範囲内へ値を変換します。ですので、下図中の左の観測は、μ-lowを適用し離散化と埋め込みベクトルへ変換します。右の行動は、離散化と埋め込みベクトルへの変換のみを行います。
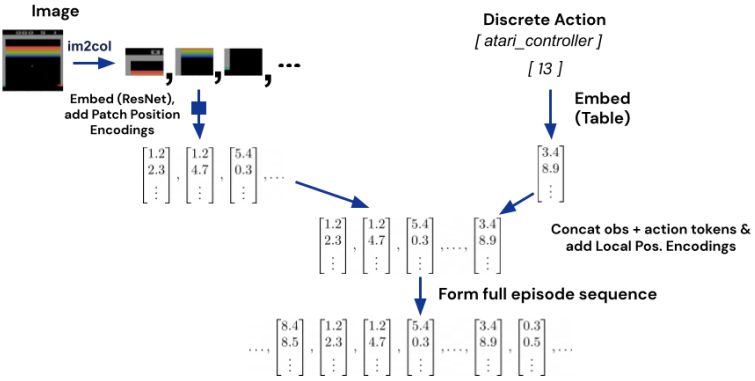
2つ目はブロック崩しの例です。観測は画像で、行動は離散値です。画像についてはパッチに分割しラスターオーダーで並べたものをResNetで個々のパッチを埋め込みベクトルへと変換します。離散値の場合は既に整数(OpenAI Gym形式のDiscrete型は整数)なので、そのまま埋め込み層で変換を行います。
系列モデル
では、系列モデル本体について説明します。Gatoで用いる系列モデルは、Transformerを用いたGPTアーキテクチャです。論文では異なるサイズの3種類のモデルが用いられていますが、中でも最も精度の高いパラメータ数が大きいもののみを紹介します。そのモデルのハイパーパラメータを以下の表に示します。
| ハイパーパラメータ | Gato(1.18B) |
| Transformer Block | 24 |
| Attentionヘッド数 | 16 |
| 埋め込み次元数 | 2048 |
| FFNの中間層数 | 8196 |
| Key/Valueのサイズ | 128 |
埋め込み次元数は2048、Transformer Blockの層数は24、Transformer Block内のフィードフォワードネットワークの中間総数は8196(埋め込み次元数の4倍)として設計されています。
損失関数
Gatoで扱う系列データ\(s\)を以下のように定義します。観測は\([y_{1:k}, x_{1:m}, z_{1:n}]\)、行動は\(a_{1:A}\)、'|'はセパレータです。
$$
s_{1:L} = [[y^1_{1:k}, x^1_{1:m}, z^1_{1:n},'|',a^1_{1:A}], \ldots, [y^T_{1:k}, x^T_{1:m}, z^T_{1:n},'|',a^T_{1:A}]]
$$
1つのデータを取り出して中身を見てみましょう。ある時刻\(t\)のデータは\([y^t_{1:k}, x^t_{1:m}, z^t_{1:n},'|',a^t_{1:A}]\)です。各要素は以下の表に示す通りです。
| \(y_{1:k}\) | 入力テキストをその順番でトークン化 \(k\)は1回の観測で受け付けるテキストのトークン数 |
| \(x_{1:m}\) | 入力画像をパッチに分割しラスターオーダーでトークン化 \(m\)は1回の観測で受け付ける画像のトークン数 |
| \(z_{1:n}\) | 離散値や連続値をトークン化 \(n\)は1回の観測で受け付ける離散・連続値のトークン数 |
| \(a_{1:A}\) | 離散値や連続値をトークン化 \(A\)は1回の行動で出力する行動のトークン数 |
これより、\(s_{1:L}\)を構成するトークン数(=埋め込みベクトルの数)は\(L=T(k+m+n+1+A)\)になります。
上記のように定義された系列\(s\)を用いて損失関数を定義します。
Gatoの学習に用いる損失関数は以下の式で表されます。
$$
\mathcal{L}(\theta, \mathcal{B}) =-\sum_{b=1}^{|\mathcal{B}|}\sum_{l=1}^Lm(b,l)\log p_\theta (s_l^{(b)}|s_1^{(b)}, \ldots, s_{l-1}^{(b)})
$$
パラメータ\(\theta\)は、埋め込み関数と系列モデルのパラメータを表しています。\(\mathcal{B}\)はバッチデータを表していて、損失を求めるときは、その中から順番に\(|\mathcal{B}|\)個のデータを取り出して計算を行います。\(b\)はバッチデータ\(\mathcal{B}\)の中に含まれるデータのインデックス、いわゆる順番を表しています。\(L\)は系列長で、\(l-1\)番目までのトークンを用いて\(l\)番目のトークンを予測するという、言語モデルのような処理を、\(l=1\)から\(l=L\)まで実施します。\(m(b,l)\)はマスク関数で、トークン\(s^{(b)}_l\)(バッチデータ\(\mathcal{B}\)中の\(b\)番目のデータの\(l\)個目のトークン)が観測と行動のどちらかを評価し、観測なら0、行動なら1になります。説明を追加すると、Gatoはオフライン強化学習エージェントであり、強化学習においてエージェントは環境から観測と報酬を受け取り行動を出力するものです。オフライン強化学習では、観測と報酬と行動を組みにして保存したデータセットを用いて学習を行います。Gatoではプロンプトによる条件付けを採用しているため報酬は用いず、観測と行動の組だけから学習を行いますが、これをそのまま言語モデルのようにして系列予測モデルを学習させようとすると、観測まで生成することになります。それを評価に含めるのは意に反するので、行動の部分(例えばテキストやロボットの関節角度など)に限定して評価するためにマスク関数\(m\)を用意しているということになります。
とても複雑な式に見えますが、本質は言語モデルの学習と同じです。以下に言語モデルの学習で用いる対数尤度関数を示します。言語モデルの場合はトークンが全て言語なので場合分けが必要ないため単純な式で表せます。
$$
\log p_\theta (s_1, \ldots, s_L) = \sum_{l=1}^L \log p_\theta (s_l|s_1, \ldots, s_{l-1})
$$
タスクとデータの収集
Gatoでは600を超えるタスクを学習させます。学習させるタスクは、次に説明する制御タスク、視覚言語タスク、ロボティクスの3つに関連するものです。それぞれのタスクはどのようなもので、そこから学習のための系列データをどのように作成したのか説明していきます。
制御タスク
制御タスクのデータにおいて特徴的なのは2つあり、1つ目はSOTAもしくはそれに近い性能を達成した強化学習エージェントを用いデータを収集したこと、2つ目は収集したデータをから質の高いデータをフィルタリングにより抽出したデータを学習に使用している点です。
フィルタリングで用いた式は以下の通りです。
$$
\max_{j\in[0,1,\ldots, N-W]}\left(\sum_{i=j}^{j+L-1}\frac{R_i}{W}\right)
$$
式において、\(N\)は収集したエピソードの総数、\(W\)は窓サイズ、\(R_i\)はエピソード\(i\)の合計報酬です。
系列データの中には、質の高い系列と質の低い系列がるので、全体の報酬の80%以上を得ることができる質の高い系列データのみを抽出して学習に使用したようです。
視覚言語タスク
視覚言語タスクでは、画像とそれに付随するテキストが記録されたデータセットが多数使用されています。使われたデータセットはALIGNやLTIP、Conceptual captionsやCOCO captionsなど多種多様です。
そして、これらから学習データを作成する必要があります。Gatoでは、5つの画像とテキストのペアをサンプリングし、それらをトークン化&連結し、学習に用いる系列長となるよう適宜パディングを追加して作成したようです。
ロボティクスタスク
ロボティクスのタスクとしては、ランダムに配置された赤青緑の3つのブロックから、緑のブロックを無視し、赤と青のブロックを積み上げるタスクを扱っています。観測はRGB画像やロボットの関節角度、姿勢情報などであり、行動はロボットやグリッパの関節角度です。
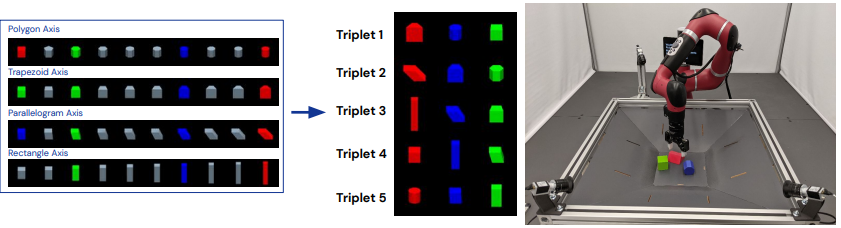
データは、高精度なモデルを用いて収集しています。収集された系列データの周波数は20Hzで20秒間の400ステップの情報です。
Gatoの汎用性
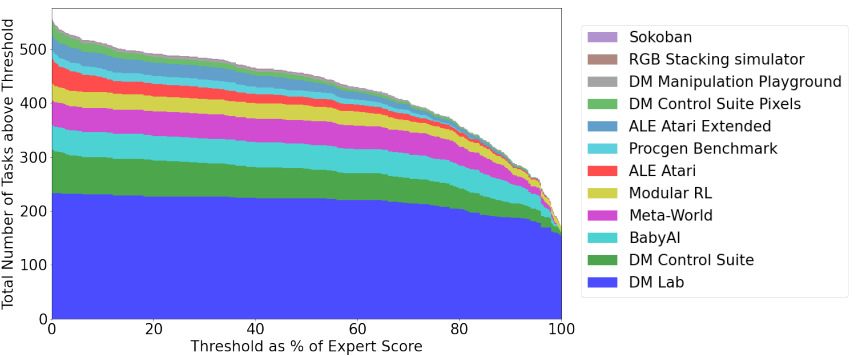
最後に、Gatoの汎用性について紹介します。下のグラフは、横軸にエキスパートのスコアを100%としたときの閾値を、縦軸はGatoが横軸の閾値以上のスコアを達成することができたタスクの数を表しています。全604個のタスクのうち、エキスパートスコアの50%を超えることができたタスクの数は450を超えています。また、エキスパートスコアの90%を超えることができたタスクの数は300程度となっています。100%を達成することができたタスクの数はギリギリ200に届かない程度ですが、単一のモデルでこれだけの数のタスクにおいてエキスパートと同程度のスコアを獲得できているのは凄いことではないでしょうか?
参考文献
[1] Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas, "A Generalist Agent," arXiv, 2022.
[2] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch. "Decision Transformer: Reinforcement Learning via Sequence Modeling, " arXiv preprint arXiv:2106. 01345, 2021.