
今回は、AlexNetの技術についてアイディアレベルで解説します。深層学習ブームの火付け役ともいえる深層ニューラルネットワーク技術についてこの機会にしっかり学んでおきましょう。
当サイトはTwitterやYouTubeでも情報発信しています。ご気軽にフォロー(@AGIRobots)、チャンネル登録お願いします!
解説動画は以下です!
AlexNetとは
まず、ILSVRCの変遷を簡単に紹介します。ILSVRCとはImageNet Large Scale Visual Recognition Challengeの頭文字をとったもので、世界規模の画像認識コンペです。2011年までは、深層学習ではない手法で認識が行われていて、2012年以降は、深層学習が先導していて、いわゆる深層学習ブームの領域です。深層学習がメインになって以降、モデルの性能はとても高くなり、それに伴って、ネットワーク自体の深さもどんどん深くなっています。ResNet以降は、それまでのネットワークの改良がメインになっています。
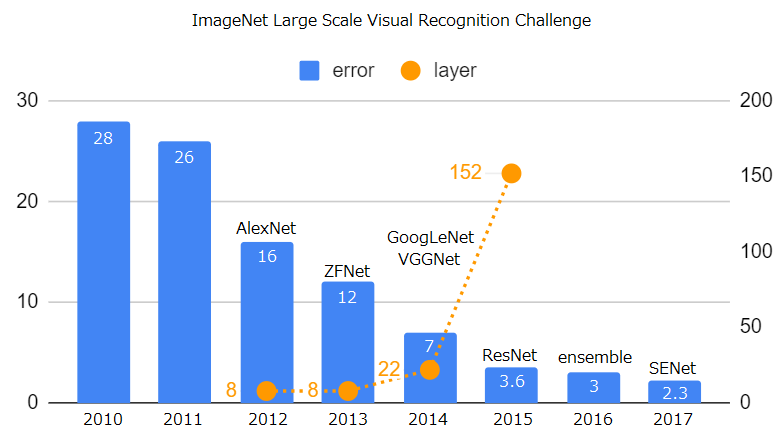
AlexNetとはILSVRC2012年のコンペにおいて、2位のモデルと大差をつけて優勝した畳み込みニューラルネットワークモデルで、Hinton教授らのチームが開発したネットワークです。AlexNetの圧倒的な勝利が深層学習ブームを引き起こしました。
AlexNetのアーキテクチャ
AlexNet自体は現在の深層学習技術と比較すると、割と簡単な構造をしています。割と簡単な構造だからこそとっつきやすく、でも様々な工夫がみられる面白いニューラルネットワークです。面白いと感じたものからアイディアレベルで紹介します。
重複付き最大値プーリングによる過剰適合抑制
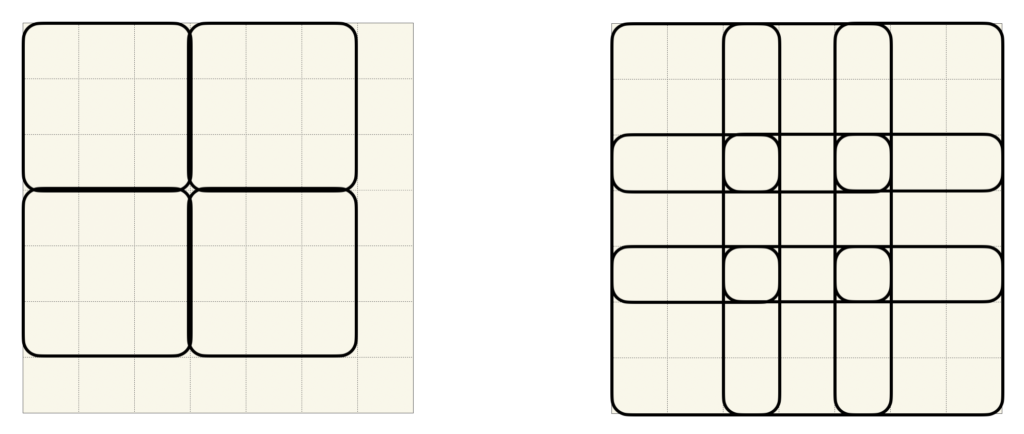
これは、個人的に面白いなと思っているのですが、ストライドのステップ幅をフィルタサイズ未満し、周囲のプーリング領域と重なるようにすると、過剰適合しにくくなるようです。まず、一般的なプーリングの場合について考えてみましょう。例えば、フィルタサイズが3の正方形と仮定すると、プーリング領域が重ならないようにストライドは最低でも3にしますよね。ここで、周辺のプーリング領域と重なりがあるようにするには、ストライドサイズがフィルタサイズ未満であれば十分な条件ですよね。人間の神経ネットワークの受容野について考えてみても、受容野に重複を持たせるというのは、合理的かと思います。あえて図示すれば以下のような感じになります。左が一般的なプーリングで、右がAlexNetで採用された重複付きプーリングです。
局所応答正規化(LRN)の使用
局所応答正規化については
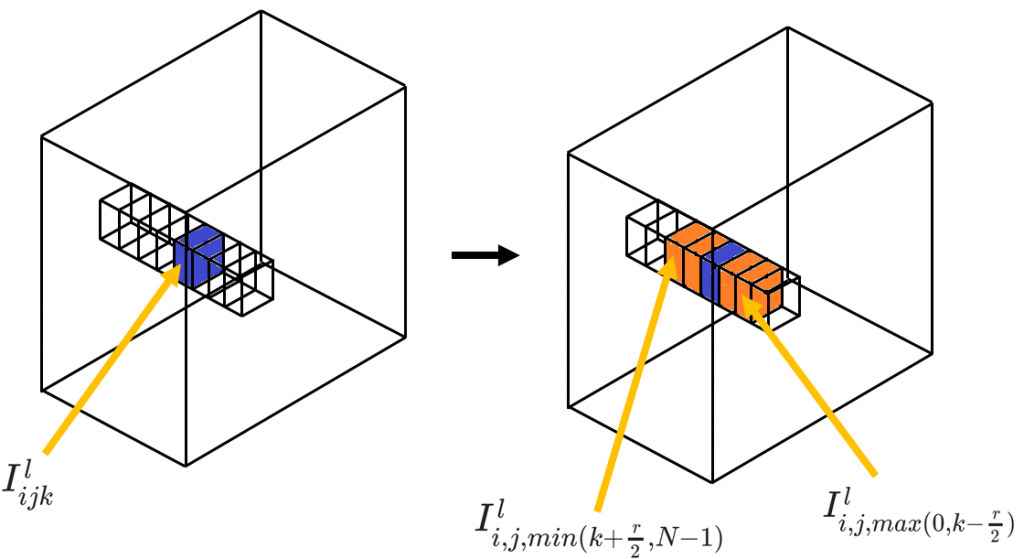
で解説をしていますので、詳しいことはそちらを読んでいただきたいのですが、簡単に説明すると、以下のような特徴マップがあったとき、チャンネル方向に正規化を行います。図では、青で塗られた部分のピクセル値\(I^l_{ijk}\)を正規化しようとしていて、その際に、\(I^l_{i,j,min(k+\frac{r}{2}, N+1)}\)から\(I^l_{i,j,max(0, k-\frac{r}{2})}\)の範囲を考慮して計算します。
具体的な計算は、以下の式に従います。
\(I_{ijk}^l = \frac{I_{ijk}^l}{\left(\kappa + \frac{\alpha}{r}\sum_{k’=max(0, k-\frac{r}{2})}^{min(k+\frac{r}{2}, N-1)}(I_{ijk’}^l)^2\right)^\beta}\)
- κ:バイアス。デフォルト値=1
- α:係数。デフォルト値=0.0001
- r:深さ半径。注目している特徴マップのチャンネルから上下どこまでのチャンネルを考慮するか決定。
- β:指数。デフォルト値=0.75
- N:特徴マップのチャンネル数。
で、式は分かったということで、じゃあ何が嬉しいの?ってことになるわけです。
畳み込みフィルターって、大量にあると、同じような特徴もつフィルタが幾つもできてしまう可能性があります。この場合、特徴が目立たなくなって公平に判断できないと思われます。特徴っていうのは際立たせたいんですよね。大げさな話、0の列の中に1がある状態(ex. 0000010000)と、8の中に9がある状態(ex. 8888898888)では、どっちの特徴の方が際立っていますかってことに帰着されると思います。これに対して、上の式のパラメータを\(r=2, \kappa=0, \alpha=2, \beta=2\)という設定で、局所応答正規化を適用してみると、以下の図のようになります。
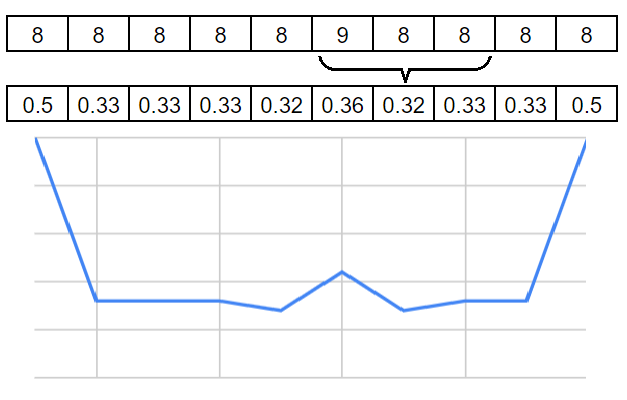
両端の8は片方が範囲外になり必然的に正規化が弱くなるので、値が大きくなっていますが、注目していただきたいのは、LRN適用前の値が9の周辺が適用後に過小評価されているところです。側抑制(周辺抑制)が行われているわけです。このように大きい特徴の周囲は過少になるようにふるまわれるところが重要な点です。
このように、LRNを使うことで、チャンネル方向に対して重要な特徴を際立たせる働きがあると考えることができます。
マルチGPUの使用
AlexNetはパラメータ数が多く、1つのGPUに値が収まらなかったということで、特徴マップをチャンネル方向に2分割して、2つのGPUに上手く計算を分けて実行しています。AlexNetの外形は以下のようになっていて、上のパスはGPU1に、下のパスはGPU2にという感じです。1つのGPUで実行するなら、2番目の特徴マップは(55, 55, 96)ですが、チャンネル方向に2分割しているので、(55, 55, 48)×2になっています。
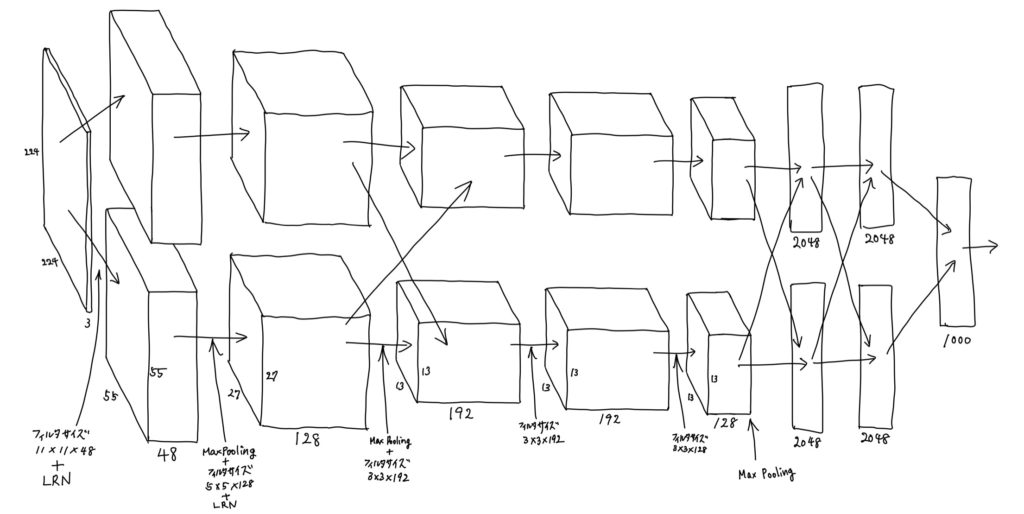
基本的には、それぞれのGPU内部で計算が完結しますが、一部は、両方の値を考慮するようにネットワークの結合があります。ここで、言いたいのは、このように、特徴マップを2分割し別々のGPUに送り込んで計算するアイディアがあるということです。
正規化線形ユニット(ReLU)の使用
AlexNetでは学習速度を向上させるテクニックとして全ての層でReLUを採用しました。現在では当たり前に使用されているので、驚きはないですが、当時としては画期的でした。
全体像
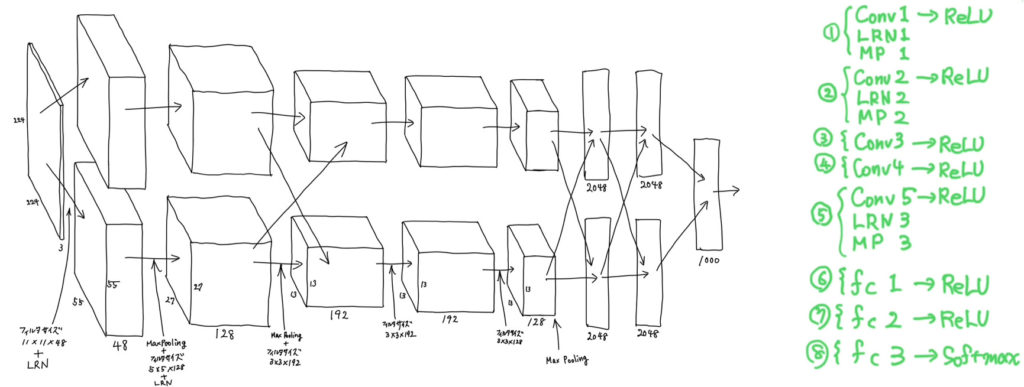
全体像ですが、まず、右のメモを見てください。8つの層のそれぞれの概要は、1層目、2層目、5層目が畳み込み計算、局所応答正規化、重複付き最大値プーリング、3層目と4層目は畳み込み計算のみ、6層目と7層目は、ReLUを採用した全結合層、8層目はソフトマックスを使った識別層になっています。左の図は、特徴マップの遷移が描かれています。これだけ見ると、どの様な処理が行われているのか分かりにくいと思います。というのも、それぞれの層を適用した直後の特徴マップが描かれているわけではないからで、具体的には畳み込み処理もしくはLRNを適用した直後の特徴マップが描かれています。ですので、例えば、(55, 55, 48)という特徴マップは、1層目の3つの処理(Conv1, LRN1, MP1)のうち、Conv1とLRN1が適用されたものです。次の(27, 27, 128)という特徴マップは、1層目の最後の処理であるMP1と2層目のConv2及びLRN2を適用した直後のものです。という感じで追っていけば理解できると思います。
最後に
本記事ではAlexNetから学べるアイディアとして、過剰適合しにくくするには重複付き、つまりOverlappingなプーリングを使うといいのでは?、ReLUに対しても局所応答正規化は効果あるのでは?、モデルが1つGPUのメモリに収まらなければ、特徴マップを分割して計算してしまおう!、学習速度向上にはReLUを使おう!という4つの観点で説明しました。ここでは触れませんでしたが、ドロップアウトだったり、学習手法だったりについても話したいことは沢山あるので、気になる方は実際の論文を読んでみてはいかがでしょうか。本記事の内容は以上になります。
次はZFNetについて扱いたいと思います。
最後までお読みいただきありがとうございました。