
今回は、畳み込みニューラルネットワークの汎化性能向上で使用されるテクニックである局所応答正規化(Local Response Normalization;LRN)について勉強したのでまとめました。
動画でもまとめているので、もし分かりにくいところがありましたら、動画も参照してみてください。
LRNとは
LRNとは畳み込みニューラルネットワークの汎化性能を上げるテクニックの1つで、特徴マップのチャンネル方向において、周囲の値を考慮した正規化を行うことで、値の大きなピクセルの周辺ピクセルが大きな値を持ちにくし特徴の競合を防いでいます。
計算式とその意味
計算式の紹介
これから説明する式は以下の記事の「畳み込み層と特徴マップの変換」の特徴マップの説明に則って数式の文字等を与えていますので、もし、分からなければこちらの該当箇所も確認いただけるとよいと思います。もちろん、見なくても分かるように努力はしますが...
\(l\)層目の特徴マップ\(I^l\)の高さ\(i\),幅\(j\),深さ\(k\)成分\(I^l_{ijk}\)のLRNについて考えてみます。このとき、LRNは以下の式で表される処理を行います。
$$
I_{ijk}^l = \frac{I_{ijk}^l}{\left(\kappa + \frac{\alpha}{r}\sum_{k'=max(0, k-\frac{r}{2})}^{min(k+\frac{r}{2}, N-1)}(I_{ijk'}^l)^2\right)^\beta}
$$
- \(\kappa\):バイアス。デフォルト値=1
- \(\alpha\):係数。デフォルト値=0.0001
- \(r\):深さ半径。注目している特徴マップのチャンネルから上下どこまでのチャンネルを考慮するか決定。
- \(\beta\):指数。デフォルト値=0.75
- \(N\):特徴マップのチャンネル数。
右にはPyTorchのtorch.nn.LocalResponseNorm()の場合におけるデフォルト値が示してあります。
計算式の意味
\(\sum\)の部分について図を使って解説します。まず、左側の図の青で塗られたピクセルに注目していると仮定します。LRNでは、チャンネル方向の同一位置にあるピクセル値を使用して正規化するための分母を計算していく多で、注目セルの上下にあるピクセルに注目します(四角の枠で示してある)。とはいえ、深さ半径\(r\)で上下チャンネルどこまで考慮すればいいか指定するため、注目ピクセルのチャンネル方向にあるピクセル全てを計算に使用するとは限りません。使用するピクセルは具体的に\(I_{ijk'}^l (max(0, k-\frac{r}{2}) \leq k' \leq min(k+\frac{r}{2}, N-1))\)の範囲です。この間に位置する値を2乗し加算しています。
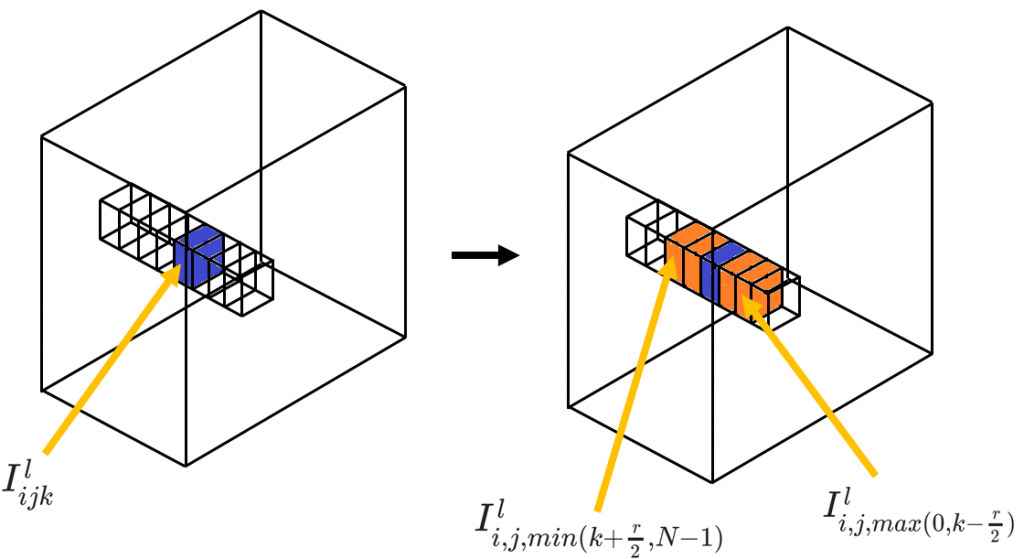
求まった二乗和の係数\(\alpha\)を乗算し、バイアス\(\kappa\)を足します。そして、\(\beta\)乗したものが、正規化の分母になります。
このように、領域を指定して計算し正規化することで、近隣に大きな値が存在すれば、周辺ピクセルの値が小さくなるように調節すること可能なようです。
これが何をやっているのか抽象的ではありますが、持論を話すと次のようになります。畳み込みフィルタに適用される前の特徴マップは、複数の畳み込みフィルタにより任意の成分がどの特徴に近いか評価されます(畳み込みフィルタでは相関を調べている)。その評価結果はそれぞれのフィルタから出力されたマップがチャンネル方向に並べらた特徴マップとして表されます。そのため、入力特徴マップの任意のピクセル及びその領域のパッチが、どの畳み込みフィルタにどのくらい評価されたかは、出力された特徴マップをチャンネル方向に見れば分かるわけです。一般論として評価値の近いものが並んでいたら、そのピクセル及びその領域のパッチに近い反応を示す畳み込みフィルタが幾つかあることが予想されるわけですが、それによって値の近いものが並んでいたら特徴がぼやけてしまう可能性があります。そのため、LRNを使用して特徴がぼやけないように、すなわち重要な特徴の周囲は反応しにくいようにしていると考えられます。このような仕組みは、生物の脳にもあり、側抑制(周辺抑制)といわれます。側抑制とは1つの神経細胞にインパルスが発生すると、周囲の神経細胞でインパルスがおこりにくいように抑制することで、入力された特徴がぼやけないように際立たせ、特徴抽出をしやすくしていると考えられます。
このように生物の脳に見られる仕組み”側抑制”をLRNが担っていると考えることができるのではないでしょうか。
実際にCNNで試す
前の記事で使用したLeNetを少し書き換えたオリジナルクラスをPyTorchで定義して前回と同じように学習を実施します。
以下のプログラムは、前の記事のOriginal_LeNetクラスからバッチ正規化処理を取り除いたものです。以下のクラスはLRNの処理がコメントアウトされています。コメントアウト部分を有効にすると、LRNありのOriginal_LeNetクラスになります。この2つを100エポック学習させました。
class Original_LeNet(nn.Module):
def __init__(self):
super(Original_LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, kernel_size=(5,5), stride=(1, 1)) # (3,32,32)→(6,28,28)
self.conv2 = nn.Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) # (6,14,14)→(16,10,10)
self.max_pool = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)) # 最大値プーリング
self.fc1 = nn.Linear(5 * 5 * 16, 120) # 線形変換
self.fc2 = nn.Linear(120, 84) # 線形変換
self.fc3 = nn.Linear(84, 10) # 線形変換
# self.lrn = nn.LocalResponseNorm(2)
def forward(self, x):
x = self.conv1(x)
# x = self.lrn(x)
x = F.relu(x)
x = self.max_pool(x)
x = F.relu(self.conv2(x))
# x = self.lrn(x)
x = self.max_pool(x)
x = x.view(-1, 5 * 5 * 16)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
結果は以下に示すようになりました。グラフを見ていただくと分かると思うのですが、両方とも性能に大差はありませんでした。
それに、LRNを使用しない方が正解率が上昇するのに要する時間が短く、その後の正解率も安定しているように見えます...(72エポック周辺でガツンと落ちてます)
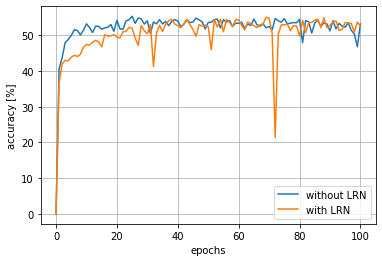
少し調べてみると、AlexNetのように特徴マップのチャンネル数が大きい(AlexNetは一部の特徴マップのチャンネル数が300を超える)ものでないと、あまり役に立たないかもしれないことと、近年ではバッチ正規化によりあまり必要性がないとの情報を見つけました。あまり重要度は高くないのかもしれません...
まとめ
特徴マップのチャンネル方向に側方抑制を行うことで汎化性能を向上させるLRNという手法があることを頭の片隅にでも置いておき、もしILSVRCに出場するような大規模なCNNを組む場合は、試してみると良いかもしれません。
また、LRNが必ずしも有効であるとは限らないことも念頭に置いておくべきかもしれません。