
多くの機械学習モデルにおいて最適化を行うとき、二乗誤差関数や交差エントロピー誤差関数などの目的関数(単に誤差関数、損失関数ともいわれる)を定める必要があります。今回は、目的関数を決めるうえで根本的な考え方の最尤推定を説明し、実際に二乗誤差関数と交差エントロピー誤差関数を導出していきます。
キーとなるポイント
今回の内容で軸となるポイントを大雑把に示しておきます。
- 誤差関数には最尤推定という考え方が根本に存在する。
- 最尤推定において、調節する対象は確率分布のパラメータである。
- 最尤推定とは訓練データを再現する確率が最も大きくなる確率分布のパラメータは何か、という考えのもと、パラメータの尤らしさを最大化することである。
- 二乗誤差関数は回帰問題で使用される。
- 交差エントロピー誤差関数は分類問題、特にロジスティック回帰やニューラルネットワークで使用される。
- 回帰問題では人が確率分布の種類を仮定する。
- 分類問題では人が確率分布の種類を仮定しない。
- 回帰問題においては、確率分布にガウス分布を仮定することが大抵である。このとき、ガウス分布のパラメータの平均値\(\mu\)(\(= \hat{y} = \boldsymbol{w}^T \boldsymbol{x}\))を推定することで、線形モデルのパラメータ\(\boldsymbol{w}\)を決定する。
- ロジスティック回帰やニューラルネットワークは出力値が確率である。つまり、モデル自体が確率密度関数である。このとき、確率分布のパラメータに対応するのは、重みや閾値である。
最尤推定
尤度
式は確率密度関数と同じですが、考え方のアプローチが異なります。図1の矢印を見てください。
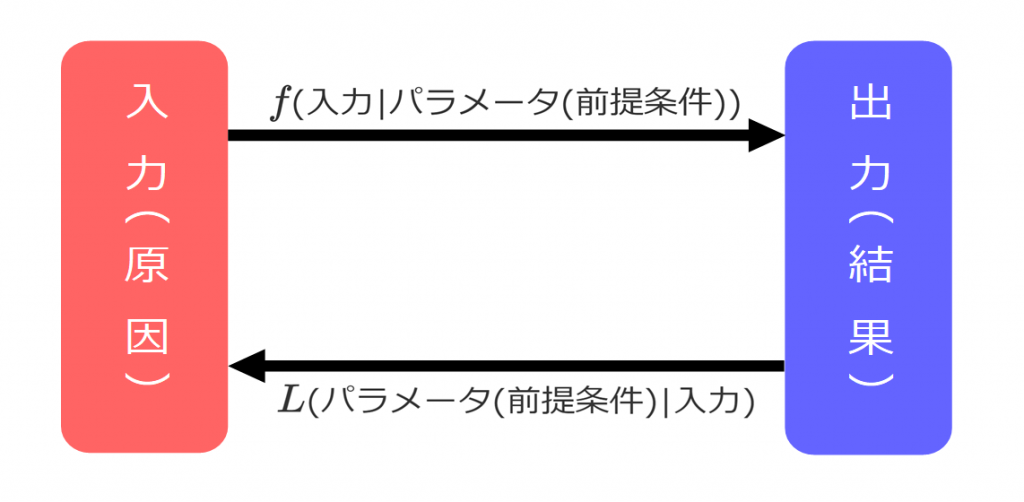
上図において入力(原因)は、確率密度関数への入力を表し、出力(結果)は、確率密度関数からの出力(確率)を表します。
式が同じと説明しましたが、厳密にいえば式は同じでも変数が異なります。例えば\(y = -ax^2 + b\)という簡単な式がありますが、\(a, b\)を定数として、入力\(x\)に対する\(y\)を出力するのが右向き矢印で、入力\(x\)が与えられた状態で、変数\(a, b\)を決めて、\(y\)を出力するのが左向き矢印です。つまり、\(y(x|a,b)\)か\(y(a, b|x)\)かの違いです。ここで、\(y(a,b|x)\)を最大化するという条件を加えたものが最尤推定です。
最尤推定
最尤推定は入力データ全体(バッチサイズによる)について、正しく回帰または分類できる確率\(P(=L)\)を最大にする、確率分布の確率密度関数または学習モデル(ニューラルネットワークなど)のパラメータを推定することです。
回帰問題の目的関数
回帰問題
回帰は連続値を予測する問題で、代表的なものに単回帰、重回帰、多項式回帰があります。更に過学習やスパース性を考慮した、リッジ回帰やラッソ回帰などがあります。
以下の図は単回帰の例です。訓練データの平均は、単回帰の線形モデル\(y = ax + b\)に、ガウス分布に従う誤差が加わったものと仮定します。
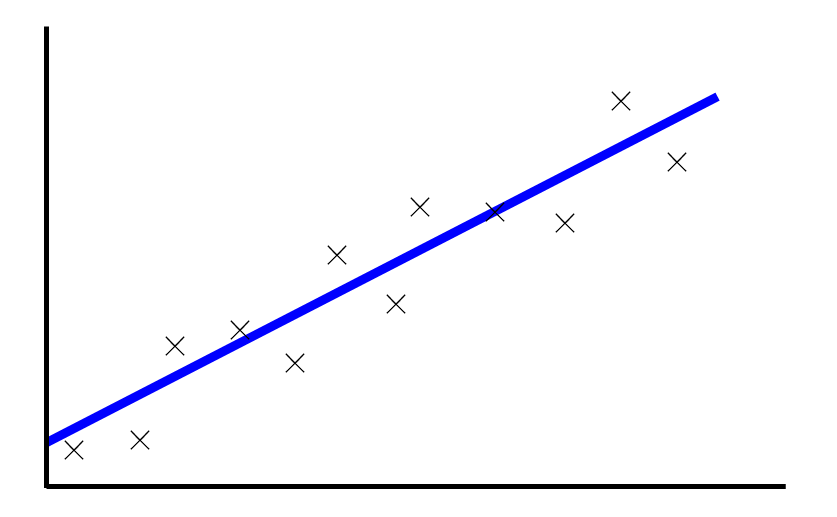
二乗誤差関数
訓練データは、線形モデルの表す超平面(または超曲面)に、ガウス分布に従う誤差が加わったものという仮定のもと、目的関数を導いていきます。どの回帰手法を使用しても二乗誤差関数は求まりますが、今回は式の複雑さが程よい重回帰を代表として考えていきます。重回帰は以下の線形モデルの式(説明変数をベクトル\(\boldsymbol{x}\)(ただし\(x_0=1\)), 重みベクトルを\(\boldsymbol{w}\)(ただし\(w_0=b(閾値)\)), 出力値を\(\hat{y}\))で表せます。
\(\hat{y} = \boldsymbol{w}^T\boldsymbol{x}\)
ここで、\(i\)番目の推測値\(\hat{y_i}\)と、実際の出力\(y_i\)の間に、正規分布に従う誤差\(\epsilon_i\)があると仮定します。
\(y_i = \hat{y_i} + \epsilon_i = \boldsymbol{w}^T\boldsymbol{x}_i + \epsilon_i\)
誤差\(\epsilon_i\)が生起する確率\(P_i\)は、
\(\begin{eqnarray}
P_i &=& N(\epsilon_i|\mu=0, \sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left (-\frac{\epsilon_i^2}{2\sigma^2}\right )\\
&=& N(y_i|\mu=\hat{y_i}, \sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left (-\frac{(y_i - \hat{y_i})^2}{2\sigma^2}\right )
\end{eqnarray}\)
と表されます。訓練データが独立同一分布に従う場合、それぞれについて掛け合わせた以下の式(同時確率)で表される多変量正規分布が確率密度関数になり、これが尤度を表します。
\(\begin{eqnarray}
L (= f) &=& \prod_iP_i\\
&=& \prod_i \frac{1}{\sqrt{2\pi}\sigma}\exp\left (-\frac{(y_i - \hat{y_i})^2}{2\sigma^2}\right )\\
&=& \frac{1}{\sqrt{2\pi}\sigma}\exp\left (-\frac{\sum_i(y_i - \hat{y_i})^2}{2\sigma^2}\right )
\end{eqnarray}\)
尤度を最大化する、つまりパラメータの尤もらしさを最も大きくしたいとき、\( \sum_i(y_i - \hat{y_i})^2 \)が最小になればよいので、回帰問題における目的関数は、
\(E = \sum_i(y_i - \hat{y_i})^2 = \sum_i(y_i - \boldsymbol{w}^T\boldsymbol{x}_i )^2 \)
になります。
分類問題の目的関数
確率分布を表現するロジスティック回帰やニューラルネットワーク
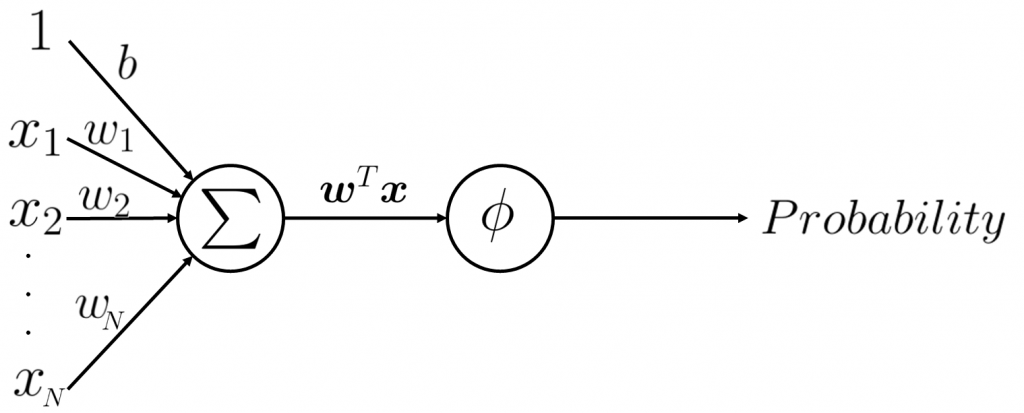
ロジスティック回帰モデルは二項分類器で、図3のモデルで表されます。ロジスティック回帰は、線形モデルに活性化関数としてシグモイド関数\(\phi\)なる非線形変換を施し、クラス1に属する確率を出力します。シグモイド関数をソフトマックス関数に変えることで2項分類の単層ニューラルネットワークになります。
ニューラルネットワークモデルの例を図4に示します。多項分類器であるニューラルネットワークは活性化関数にソフトマックス関数が使用され、それぞれのクラスに属する確率を出力します。
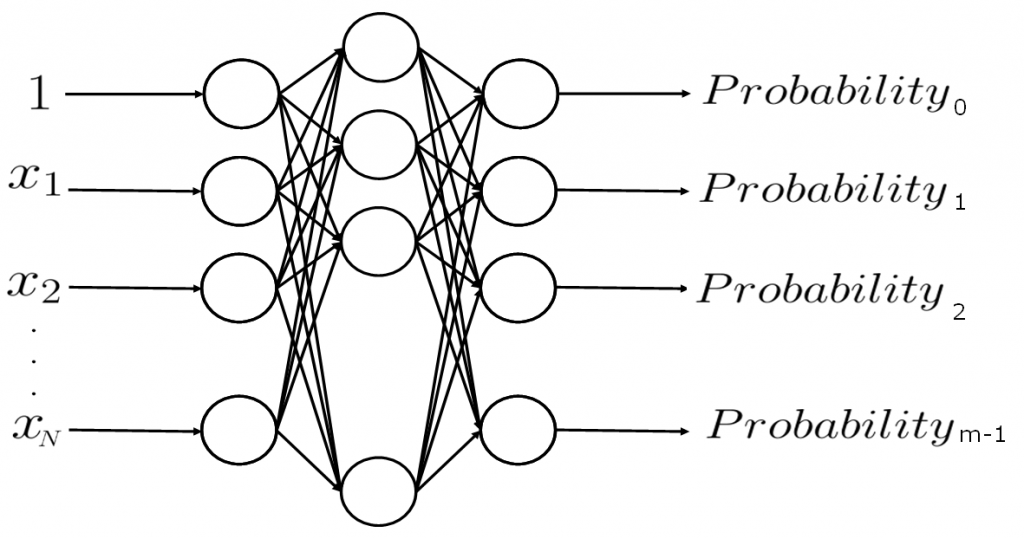
これら二つは、入力を受けて確率を出力するので、確率密度関数といえます。そのため、重みベクトルを学習することは、確率密度関数のパラメータを決定すること同じです。
交差エントロピー
ロジスティック回帰の目的関数を求めたいと思います。ロジスティック回帰では二項分布を扱うため、教師信号はクラス0(\(t=0\))とクラス1(\(t=1\))です。\(i\)番目の入力データを\(\boldsymbol{x}_i\)(ただし\(x_0=1\))、教師信号を\(t_i\)、重みベクトル\(\boldsymbol{w}(ただしw_0=b(閾値))\)とするとき、クラス1に属する確率\(p_i\)は
\(p_i = \phi(\boldsymbol{w}^T\boldsymbol{x}_i)\)
で表せます。ここで、\(p_i\)はクラス1に属する確率なので、クラス0に属するときはクラス0に属する確率を出力するように以下のように\(P_i\)定めます。
\(P_i = p_i^{t_i}(1 - p_i)^{(1 - t_i)}\)
全てのデータ(それぞれ独立同一分布と仮定)につてい正しく分類する確率は、
\(L (=P) = \prod_iP_i = \prod_ip_i^{t_i}(1 - p_i)^{(1 - t_i)} \)
となります。つぎに、情報理論で使用される情報量の概念を使用し、
\(E = \log\frac{1}{P} = -\log P = -\log L\)
のように定めます。情報量は以下の性質
- 情報量が大きい → 生起確率\(P(=L)\)が小さく、その事象は珍しい。
- 情報量が小さい → 生起確率\(P(=L)\)が大きく、その事象は高い確率で生起する。
があるため、訓練データに適合するには情報量が小さくなればよいことが分かります。つまり、情報量\(E\)が最も最小になるように学習を行えば自ずとパラメータの尤もらしさ(尤度)が最大になります。よって交差エントロピーは、
\(\begin{eqnarray}
E &=& -\log L\\
&=& -\sum_i\{t_i\log p_i + (1 - t_i)\log (1 - p_i)\}
\end{eqnarray}\)
になります。
まとめ
多くの機械学習モデルでは最適化にあたり目的関数が必要です。今回、目的関数が最尤推定に基づいていることを確認することで、回帰問題と分類問題の関連性を改めて認識することができました。今後も最尤推定は常に頭の片隅に置いておきたいですね。